
英语原文共 15 页,剩余内容已隐藏,支付完成后下载完整资料
关于3D和多模态3D 2D人脸识别方法的研究
1.摘要
这项调查的重点是通过匹配脸部三维形状的模型来识别人脸,或者是单独的二维强度图像的组合。目前的研究趋势已经有所总结,现在对更精确的三维人脸识别的发展提出了挑战,包括对更好的传感器,改进的识别算法以及更加严谨的实验方法。
2.介绍
类似于FRVT的评估明确了当前的面部识别的技术发展还不足以满足要求日益苛刻的实际应用。然而,生物识别技术现如今精确度越来越高,比如指纹和虹膜识别,需要用户更精确的合作。比如,指纹需要合作者与传感器表面进行物理接触,这就提出了如何在高吞吐量的应用程序中保持表面清洁和无菌的问题。现如今的虹膜图像识别要求合作者将自己的眼睛放置于传感器的有效位置。对于一个高通量应用程序,这也会导致很多问题。因此为了提高人脸识别的性能,有很大的潜在应用驱动需求。由不同国家政府机构发起的人脸识别大挑战项目的其中一个目标就是在FRVT2002年记录的人脸识别性能的基础上能有一个数量级的增长。
绝大多数的面部识别研究和商业面部识别系统使用的是典型的面部强度图像。我们把他们称为“二维图像”。相反,人脸的“三维图像”代表3D图形。最近对人脸识别研究进行了广泛的调查,但不包括基于匹配3D形状的研究工作。我们的这里的研究特别集中于研究3D人脸识别。这是对于之前版本的升级和拓展,包括人脸识别大挑战一开始得出的一些研究结果和最近的发现。Scheenstra等人对早期的一些3D人脸识别工作做了一些替代研究。
我们之所以对3D人脸识别特别感兴趣是因为大家普遍认为使用3D识别比使用2D识别有着更高的精确度。比如,有一个说法,“因为我们在三维空间进行研究,我们克服了视角和光线变化的限制”。另一篇文章这样来形容3D人脸识别:“范围图像具有捕捉形状变化而无需考虑光线变化的优点”。同样的,另外一篇文章这样说到:“深度和曲率的特点相比传统的基于强度的图像有更多的优点”。特别是曲率描述量:(1)在描述基于表面的事物时有更精确的可能(2)更适合描述脸部一些区域的特性,比如脸颊,额头和下巴(3)不受视角变化影响。
3.背景概念和术语
“面部识别”的一般概念适用于不同的应用场景。一个场景可以称作为识别,另一个场景可以称为身份验证。在这两种情况下,已知的人的面部图像首先被纳入系统。这一组人有时候被称为“图库”。之后的这些人或者其他人的图像被用作探测器在图库中进行匹配。在识别场景中,这种匹配是一对多,在某种意义上,一个探测器匹配图库中所有的图像寻找某种阈值之上的最佳匹配。在身份验证场景中,这种匹配是一对一,在某种意义上,如果匹配的质量超过某个阈值,那么就会将探测与通道条目相匹配,并对其进行身份验证。识别场景比身份验证场景更具有技术上的挑战性。一个原因是在识别场景中,一个较大的图库往往更可能出现错误识别。另一个原因是,整个图库必须以某种方式对每个识别进行尝试搜索。
尽管研究结果可能在识别或验证的背景下呈现,但3D表示和匹配问题的核心在本质上是相同的。事实上,识别实验的累积匹配特性(CMC)曲线的原始匹配值可以很容易地以不同的方式进行制表,从而生成一个认证实验的接受者操作特征(ROC)曲线。CMC曲线总结了一组被认为是正确匹配的探测器的百分比作为被认为正确匹配的匹配等级的函数。rank-1识别率是CMC曲线中最常见的数值。ROC曲线总结了一组被错误地拒绝的探测器的百分比,作为对被错误接受的百分比的权衡。等错误率(EER),即误拒绝率等于误接受率的点,是ROC曲线上最常见的单数值。
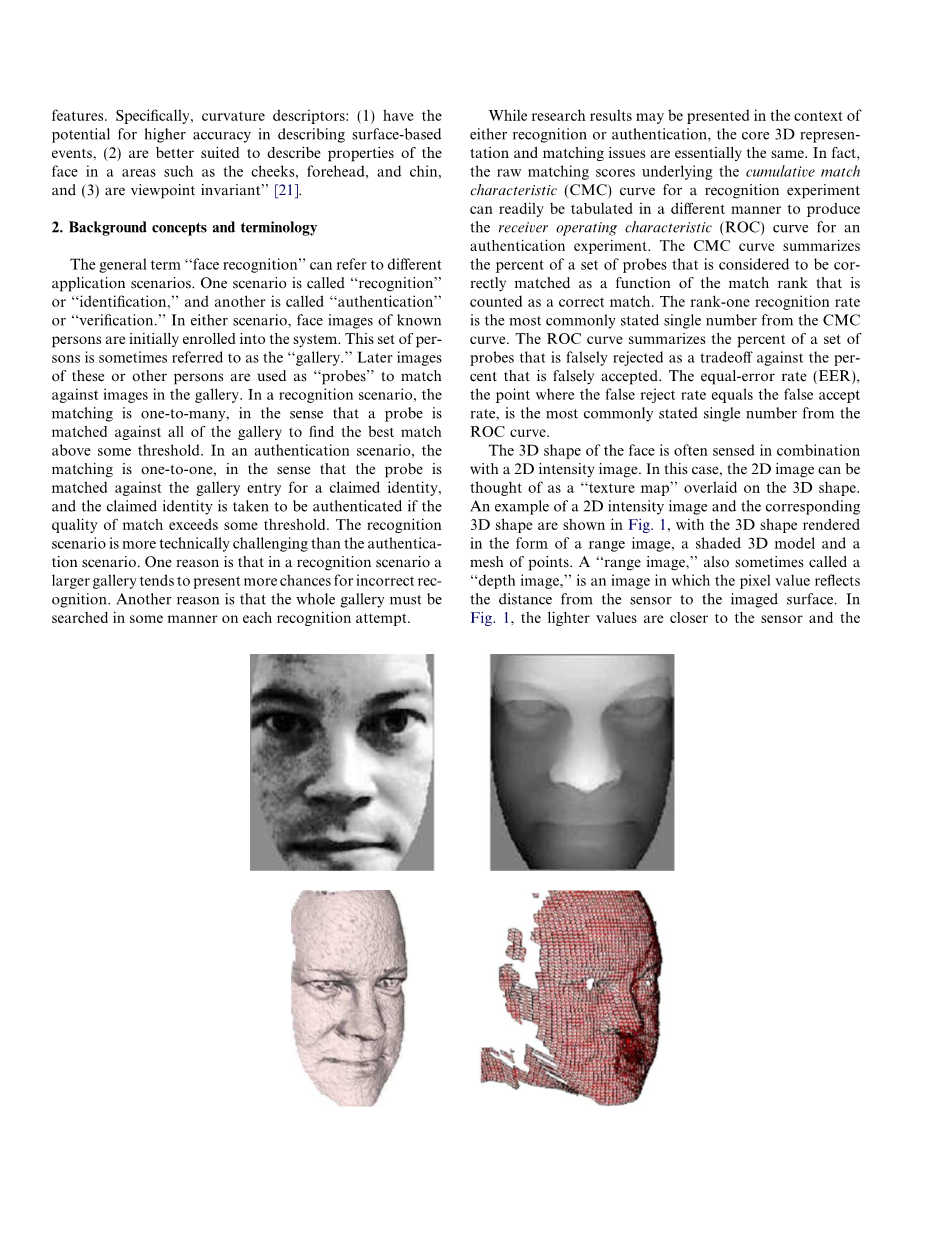
面部的三维形状通常与二维的强度图像相结合。在这种情况下,2D图像可以被看作是一个覆盖在3D图形上的“纹理贴图”。图1展示了一个二维强度图像和相应的3D图形的例子,三维图形以一个距离图像,一个阴影3D模型和一个网格点的形式呈现。“距离图像”有时也被称为“深度图像”,它的像素值反映了从传感器到图像的距离。在图1中,较轻的值更接近传感器而较暗的值则更远。一个范围图像,一个阴影模型和一个线框网格是用来显示三维形状数据的常用方法
一般来说,多模态生物识别技术指的是使用多种成像方式,如3D和2D图像。“多模态”这个术语在这里可能不太准确,因为这两种类型的数据可能是由同一个成像系统获得的。在这个调查中,我们考虑了多模态三维和二维人脸识别的算法以及只使用三维图形的算法。在这里我们不考虑使用一种通用的,“morphable”的3D面部模型作为一个中间步骤来匹配两个二维图像以实现人脸识别。这种方法是由Blanz和Vetter推广开来的,在FRVT的2002年的报告中对这种方法进行了研究,这种类型的方法已经在各种各样的商业面部识别系统中使用了。然而,这种方法不涉及到三维形状描述的传感或匹配。相反,二维图像被映射到可变形的3D模型上,而带有纹理的3D模型则用于为匹配过程生成一组合成的二维图像。
4.完全基于三维形状的识别
表1选择了一些算法进行比较,这些算法仅使用3D图形来识别人脸。作品按出版时间和第一作者的姓名首字母的顺序排列。这个领域最早的工作是在十年前完成的。在90年代,这一领域的工作相对较少,但近年来的活跃程度有很大提高。
大多数论文报告的性能都使用一种公认的识别率,尽管有些报告的误报率或验证率是按照指定的误接受率进行的。从历史上来看,这个领域的实验成分相当有限。实验数据组中所代表的人数直到2003年才达到100人。只有少数作品处理的数据集明确地包含了姿态和或表情变化。因此,大多数早期的作品都有100%的识别率,这也许并不令人惊讶。然而,面部识别大挑战计划使得几个研究小组在一个共同的数据集合上发布结果,这个数据组代表超过400个人的4000个图像,在面部表情上也有很大的变化。FRGC版本的两个资料组展示的不同的表情如图2所示。随着实验数据变得越来越庞杂越来越具有挑战性,算法也变得越来越复杂,而报告的识别率却并不像之前的一些作品那么高。
Cartoux等人通过对一个基于主要曲率的范围图像进行分割来进行3D人脸识别,并且找到了一个通过面部的左右对称的平面。这个平面是用来使姿态正常化的。他们考虑的方法是匹配对称平面上的轮廓和匹配人脸表面,并在任意一个小数据集里报告100%的识别。
李和milios分割出了一个基于平均值和高斯曲率的图像上的凸区域,并为每个凸区域创造了一个扩展的高斯图像(EGI)。在探测图像中的区域和图库中的图像的匹配是通过关联EGI来完成的。EGI是通过物体表面法线的分布来描述物体的形状的。一个利用关系约束的图形匹配算法是用来建立探测图像对图库图像的整体匹配的。相比其他区域,凸区域随着面部表情的变化形状改变更小。这就给了我们一些处理面部表情变化的能力。然而,EGI对物体大小的变化并不灵敏,所以两个相似的形状但是不同大小的脸在这种表示中是无法区分的。
Gordon以一个基于曲率的脸部分割开始。然后,提取一组特征值来描述脸部的曲率和尺寸属性。因此,每个面都成为了特征空间中的一个点,并且完成了最近邻的匹配。据报道,实验结果显示,8个人脸的3个视图和识别率高达100%。我们注意到,所使用的特征值通常与同一张脸的不同图像相似,“除了具有较大特性检测错误或者表情变化的情况”。
Nagamine等人通过找到五个特征点来进行人脸识别,使用这些特征点来标准化面部姿势,然后通过面部数据匹配不同的曲线或轮廓。实验有16个实验对象,每个对象有10张图片。最好的识别率是通过垂直的轮廓曲线穿过脸部的中心部分。这项工作需要极大的计算量。正如作者所指出的那样,“考虑到需要大量的计算和硬件能力,使用整个面部数据基本上是不可能的。”
Achermann等人扩展了用于2D人脸识别的特征面部和隐藏的Markov模型(HMM),以处理深度图像。他们为一个24人的数据集显示结果,每个人有10个图像,并通过使用2D人脸识别算法报告100%的识别率。
Tanaka等人也执行了基于曲率的分割,并使用扩展的高斯图像(EGI)来表示脸部。识别是通过使用EGI的球形相关性来进行的。据报道,加拿大国家研究委员会的一组37幅深度图像报告了100%的识别率。
Chua等人在3D人脸识别中使用“点签名”。为了处理面部表情的变化,只有从鼻子下面的那部分几乎僵硬的脸被用于匹配。点签名的作用是定位用于标准化姿态的参考点。实验使用不同的6个实验对象的不同表情对应的多种图像,并报告了100%的识别率。
Achermann and Bunke报告了一种使用了豪斯多夫距离匹配的3D人脸识别方法。他们在实验中使用了24个人每人的10个图像,共240个深度图像,并对算法的某些案例实现了100%的识别。
Hesher等人使用不同数量的特征向量和图像大小来探索主组件分析(PCA)方法。所使用的图像数据包括37个实验对象的6种不同的面部表情。这些性能数据报告的结果来自于图库中的每个对象对应的多个图像。这就有效的增加了探测图像更多正确识别的可能,已知的是提高了相对于每个对象的单个样本的识别率。
Waupotitsch和Medioni使用了一种迭代的最接近点(ICP)方法来进行面部识别。在这里,大部分的工作是通过一个结构光传感器获得的三维图形,这个工作使用的是一个被动的立体声传感器所获得的三维形状。通过对一组100个实验对象、每个对象的7张图片进行了实验,其中7张图片分别是不同的姿势。等错误率(EER)高于2%。
Moreno和他的同事们首先通过基于高斯曲率的分割来实现3D人脸识别,然后根据分割区域创建一个特征向量。他们报告了一组60个人的420个面部图像的数据集,其中每个人都有不同的表情和姿势。在主视图的子集中实现了rank-1的78%的识别。
李等人通过定位鼻尖来进行3D人脸识别,然后在一个深度值序列的基础上,形成一个基于轮廓的特征矢量。他们报告了94%的正确识别,但是没有报告rank-1的识别。其识别率在1级和5级之间会发生巨大的变化,因此不可能在一级的情况下对这种方法进行评估。
Pan等人使用了Hausdorff距离方法和基于主成分分析的方法来进行人脸识别。在M2VTS数据库的图像中,他们报告了对于Hausdorff距离方法等错误率(EER)在3-5%,对于基于主成分分析法的方法等错误率(EER)在5-7%。
李和Shim考虑使用“深度加权的豪斯多夫距离”和表面曲率信息(最小、最大和高斯曲率)来进行3D面部识别。他们提出了一组代表42个人、每个人两幅图像的实验结果。他们研究的最有效的组合方法的rank-1识别率达到了98%,而普通的Hausdorff距离方法的识别率则不到90%。
Lu等人报告了基于ICP的3D人脸识别方法的结果。这种方法假设图库的3D图像是一个更完整的人脸模型而探测器三维图像是一个正面的视图,很可能是图库图像的一个子集。通过对18人的图像进行实验,对每个人进行多幅探测图像,在姿态和表情上进行了一些改变,达到了97%的识别率。
Russ等人展示了在深度图像上进行Hausdorff匹配的结果。他们使用在实验中使用的数据的一部分。在一个验证实验中,图库中包括200个人,同样的200人和另外68个诈欺模型在探测组中。在错误的警报率为0的情况下(68人),正确的验证率高达98%(200人)。在一个识别实验中,有30个人被记录在图库中,然后这30个人在随后的时间里被探测。在错误的警报率为0的情况下,获得识别的概率为50%。由于当前算法的计算成本,识别实验使用了可用数据的子集。
徐等人开发了一种三维人脸识别的方法,并利用Beumier和Acheroy的数据库对其进行了评估。最初的3D点云被转换成一个普通的网格。鼻子区域被发现并用作寻找其他地方的锚点。特征向量是由嘴、鼻子、左眼和右眼的局部区域的数据计算出来的。利用主成分分析,减少了特征空间的维数,并且利用全局和局部的形状分量来匹配最小距离。实验结果为数据集的120个人和30个人的一个子集报告,分别表现为72和96%。这说明了报告的实验性能高度依赖数据集的大小。大多数其他的研究都没有考虑到数据集大小对性能的影响。值得一提的是,报告的表现是通过在图库中记录的一个人的五幅图像获得的。通常情况下,如果只用一幅图像来记录一个人,性能表现会更低。
Bronstein等人提出了一种接受面部表情引起的形变的3D人脸识别方法。他的想法是将3D面部数据转换成一个不随建模形状变化的特征形态。实际上,有一种假设是“由于面部表情而导致的距离的变化是微不足道的。” 实验评估是用一个包含了220张30人的图像(27个真人和3个人体模型)的数据集进行的,并且报告了100%的识别率。在30个对象中总共使用了65个记录图像,因此一个对象被多个图像所表示。正如前面提到的,每个人使用一个以上的记录图像通常会提高识别率。该方法可以与同一主题的二维特征面方法相比,但空间方法仅使用35个图像、23个维度。该方法也与刚性表面匹配方法进行了比较。也许这项工作最不寻常的地方在于,这种方法“能够区分同卵双胞胎”。
Gouml;kberk等人使用Beumier 和Acheroy数据的子集比较了五种3D人脸识别的方法。他们比较了基于扩展高斯图像、ICP匹配、范围概况、PCA和线性判别分析(LDA)的方法。他们的实验数据包括271张来自106人的图片。他们发现ICP和LDA方法提供了最好的性能,尽管除了PCA以外所有的方法性能都比较相似。他们还融合了五种方法并且能够通过识别者的组合实现99%的rank-1识别。该算法在比较不同的三维人脸识别算法的性能方面比较新颖,并通过结合多种算法实现了性能的提高。探索这类问题的额外工作似乎是有价值的。
Lee等人提出了一种基于8个特征点的曲率值的3D人脸识别方法。使用支持向量机进行分类,他们报告了一个代表100人的数据集的rank-1识别率。他们使用一个网络软件传感器来获取注册图像和一个Genex传感器来获取探测图像。识别结果被称为“模拟”结果,显然是因为这些特征点是手动定位的。
Lu和Jain使用基于icp辨识的识别方法来扩展之前的工
全文共17159字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[14477],资料为PDF文档或Word文档,PDF文档可免费转换为Word
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

