
英语原文共 9 页
使用微调深度网络融合的乳腺癌组织学图像分类
Amirreza Mahbod1,2(B), Isabella Ellinger1, Rupert Ecker2, Orjan Smedbyuml; 3, and Chunliang Wang3
1
Institute of Pathophysiology and Allergy Research, Medical University of Vienna,
Vienna, Austria
2
Department of Research and Development, TissueGnostics GmbH, Vienna, Austria amirreza.mahbod@tissuegnostics.com
3
Department of Biomedical Engineering and Health Systems,
Division of Biomedical Imaging, KTH Royal Institute of Technology,
Stockholm, Sweden
摘要
乳腺癌是全世界妇女最常见的癌症类型。即使对经验丰富的病理学家来说,乳腺活检的组织学评估也是一项具有挑战性的任务。本文提出了一种将乳腺癌组织学图像分为正常、性、原位癌和浸润癌四类的全自动分类方法。该方法以归一化的苏木精和伊红染色图像为输入,通过融合两个不同深度的残差神经网络(resnet)的输出进行最终预测。这些ResNets首先在ImageNet图像上进行了与训练,然后再乳房组织学图像上进行了微调。我们发现,我们的方法在应用于BioImaging 2015 Challenge数据集时,比以前发布的方法大幅度提高,精确度为97.22%。此外,同样的方法在应用于ICIAR 2018年大挑战数据集(采用5倍交叉验证)时提供了出色的分类性能,准确率为88.50%。
关键词:乳腺癌组织学图像分类深度学习
1引言
乳腺癌是妇女中最常见的癌症。此外,它在女性癌症死亡中排名第一[1]。早期发现乳腺癌是至关重要的,因为90%以上的早期诊断为乳腺癌的妇女至少能在疾病中存活5年。相比之下,远端器官肿瘤转移基本上是不可治愈的,并导致超过90%的癌症死亡。因此,在许多国家,乳腺摄影等筛查方法已被实施为早期癌症检测的重要工具,以降低乳腺癌死亡率[2,3]。
copy;Springer International Publishing AG, part of Springer Nature 2018
A. Campilho et al. (Eds.): ICIAR 2018, LNCS 10882, pp. 754–762, 2018.
https://doi.org/10.1007/978-3-319-93000-8_85
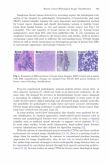
通过筛查发现的可疑乳腺病变需要病理学家对活检进行组织学评估。苏木精和伊红(Hamp;E)染色样本的检查仍然是乳腺癌诊断的最重要和最基本的方法,而且能将正常或健康的乳腺组织与良性病变、原位和浸润性乳腺癌区别开来(示例见图1)。绝大多数乳腺病变是良性的。在乳腺恶性肿瘤中,95%以上来自上皮细胞。原位癌是仍局限于乳腺导管和小叶的肿瘤性病变,而在浸润性癌中,肿瘤细胞开始浸润周围组织。总的来说,良性病变和乳腺癌都是在微观外观和生物学行为上不同的异质性病变群[5,6]。
图1不同形式的乳腺组织活检样本,Hamp;E染色,放大200倍获得。(图片改编自ICIAR 2018年乳腺癌组织学分类大挑战)。
即使对于经验丰富的病理学家,手工分析也会导致观察者内部或观察者之间的差异[7],这可能导致评估不准确。同时,组织病理学乳腺癌诊断的准确性要求也在不断提高。此外,世界上许多地方缺乏病理学家。在这种情况下,数字病理学和自动图像分析工具为病理学家提供了更快更准确的评估的可能性。在各种图像处理技术的帮助下,组织病理学乳腺癌的诊断在过去几年中有了进一步发展[8]。
在一些研究中,细胞核水平信息(细节)被用来进行组织分类。在经典方法中,提取手工制作的核特征(如纹理和形态特征)以训练经典分类器(如人工神经网络或支持向量机[9-11])。在其他一些研究中,除了核信息外,还利用手工制作的组织特征(背景信息)进行算法训练[12]。
随着卷积神经网络(CNN)的出现及其在自然图像分类方面的优异性能[13,14],将其应用于医学图像的趋势越来越明显。与传统的图像分类机器学习方法不同,它们不依赖手工制作的特征,而是利用大量的图像来获得任务特定的图像特征,这些特征可以通过其特殊的收缩结构由卷积核表示[13,14]。文献报道了几种利用CNN进行乳腺癌组织学图像分析的研究。在大多数早期的研究中,使用CNN对斑块分类进行了研究,而图像分类则基于斑块概率的组合。补丁大小在不同的研究中有所不同(例如从32times;32到512times;512),并且在大多数情况下,一个新的CNN架构从零开始就在有限的数据集上进行了培训。[15–18]。
在本研究中,我们提出了一种完全自动化的计算机化方法,该方法基于神经网络融合,将乳腺组织学图像分为四类,包括正常组织、良性病变、原位癌和浸润癌。在我们的方法中,我们不从零开始训练相对较小的CNN,而是使用在ImageNet上预先训练过的深度神经网络[19]。这项工作是基于我们以前对皮肤病变分类的多个CNN集合的研究[20],扩展了对有限的乳腺癌组织学图像训练集的网络微调。与之前使用图像补丁的研究不同,我们将整个调整过大小的图像输入到网络中。为了提高训练分类器的鲁棒性,我们还对几种归一化技术进行了实验。
2材料和方法
我们提出的乳腺癌组织学图像分类方法包括两个主要步骤:图像预处理和标准化,以及基于深度学习的图像分类。在下面的小节中,我们详细描述了我们方法的所有步骤。 2.1数据集
我们在这项工作中使用了两个数据集,即生物成像2015年挑战(BI)数据集和ICIAR 2018年大挑战(ICIAR)数据集。第二个数据集是第一个数据集的扩展版本,两个数据集都包含24位rgb hamp;e染色的乳房组织学图像,像素大小为0.42mu;mtimes;0.42mu;m,放大200倍获得并从整个幻灯片图像活检中提取。两组数据都包含四种不同类型的乳腺癌组织学图像,即正常组织、良性病变、原位癌和侵袭性癌。第一个数据集包含249个训练图像,这些图像平均分布在四个类别中。它还包含36个测试图像,分为两组,即初始组(20个图像分类难度较小)和扩展组(16个图像分类难度较大)。第二个数据集在每个类中包含100个图像,即总共400个培训图像,其中包括来自BI数据集的培训和测试图像。提交本报告时,第二个数据集的测试图像远离挑战参与者,并将用于挑战组织者对不同方法的评估。所有数据集中每个图像的大小为2048times;1536像素。两位医学专家对图像进行了标记,病理学家之间存在分歧的图像已被弃用。
2.2预处理
在我们提出的方法中,我们使用了两个主要的预处理步骤,然后将图像传送到深层网络:
归一化。染色变异在组织学图像中很常见。这是由于许多因素造成的,例如化学制剂制造商的变化、使用前的储存条件和染色方案[21]。这种染色变异性的一些例子如图1所示。为了解决这一问题,我们尝试了两种不同的归一化技术,以减少颜色方案的变化,提高后续分类方法的鲁棒性。这两种方法是:
RGB柱状图匹配:我们从数据集中选择一个随机参考图像,并计算每个单独的RGB通道的所有强度级别的累积柱状图,然后,我们相应地匹配所有其他训练和测试图像的RGB柱状图[22]。虽然在直方图计算过程中同时使用了参考图像和目标图像的背景像素,但在变换过程中忽略了背景像素。对于背景检测,采用了Otsu的阈值方法[23]。
Macenko等人方法[21]:将参考图像和目标图像的RGB值转换为最佳密度(OD)。接下来,删除强度值小于阈值beta;的部分数据。然后,将奇异值分解(SVD)应用于OD元组。在下一步中,使用来自SVD方向的两个最大值创建一个平面,然后将数据投影到创建的平面,以形成染色分离向量。利用代表参考图像Hamp;E染色的染色分离矢量改变目标图像的Hamp;E强度值。有关此方法的更多详细信息,请参见[21]。与RGB直方图匹配类似,在此预处理步骤中背景像素保持不变。
应用上述标准化技术后,我们从所有训练和测试图像中减去ImageNet数据集的平均RGB值,因为我们方法中使用的网络最初是在该数据集上进行训练的[13]。
调整大小。利用的深度预训练网络与完全连接(fc)层期望输入图像有一定的大小。因此,我们使用双三次插值将所有图像调整为适当的大小(224times;224)。在调整大小的过程中,原始图像的纵横比发生了更改。
2.3 CNN微调与融合
我们使用了两个成熟的预先培训过的深CNN,resnet-50和resnet101[14],它们在自然图像分类方面表现出出色的性能。深层剩余网络有一种特殊的层结构,称为具有快捷连接的剩余块,然后是网络顶部的FC层。Resnet-50有17个剩余块,而Resnet-101更深层,包含33个剩余块。有关这些网络的架构的更多详细信息,请参见[14]。由于这些网络最初是在数十万张自然图像上进行训练的,因此不可能直接用于更大的组织学图像分类。因此,我们采用了转移学习的方法,通过在自然条件下训练神经网络,并在胸组织学上对神经网络进行微调,以充分利用神经网络中的神经网络分类问题。
为了进行微调,我们删除了网络的最后一个FC层,并用两个新的带有64个和4个节点的FC层替换它们,以对4个类执行分类。这些新增加的层的重量是从高斯分布中随机选择的,平均值为零,标准偏差为0.01。然后,我们对所有层(包括fc层和卷积层)进行了再培训,但是新的fc层的学习速率(lr)比所有其他可学习层都大10倍。利用动量随机梯度下降和L2正则化项对网络进行微调。我们选择了0.001的初始lr,在每5个时期后下降了10倍。我们选择0.0001的权重衰减和0.9的动量进行优化,并将网络重设25个时期。
为了防止网络过度适应我们有限的数据集,我们通过数据扩充人为地增加了我们的训练数据量。我们使用旋转(0、90、180和270)和水平翻转作为主要增强技术。在测试数据的推理阶段,我们应用了类似的数据增强技术。这意味着8个图像(旋转和水平翻转图像)是从一个测试图像创建的,并被送入微调网络。选择应用于这些图像的网络平均输出概率作为特定测试图像的最终分类结果。
此外,我们还测试了网络融合方案,以观察其对方法性能的影响。为了融合测试图像上的结果,我们对网络的预测向量取了平均值。
2.4评价
通过计算所有四个等级的总体精度,对所提出的方法进行评估,这也是BI和ICIAR挑战中的主要评估指标。为了获得整体的准确度,我们在每个测试图像的每个4个元素预测向量中选择最大值,然后将其对应的标签设置为该方法的选择类。
3结果
本节报告的结果来自BI和ICIAR数据集。对于BI数据集,36个提供的测试图像被用于评估,包括20个简单样本(初始组)和16个具有挑战性的案例(扩展组)进行分类。对于ICIAR数据集,由于在提交本文时没有可用的测试数据,我们对训练集使用了5倍交叉验证,并平均了所有测试折叠的准确性。由于其中一个数据集是另一个数据集的扩展版本,因此我们隔离了用于报告结果的网络(即,第二个数据集的训练网络不用于评估第一个数据集的测试数据)。
我们从研究标准化对总体性能的影响开始实验。该部分针对BI数据集的总结结果如表1和表2所示。这些表中的结果是通过运行整个算法5次并取网络输出的平均值得到最终分类预测的。由于我们使用RGB直方图匹配归一化技术观察到了更好的总体性能,因此在进一步的实验中我们没有使用其他归一化技术。
表1。各种规范化技术对精度(acc)的影响(使用微调的resnet-50应用于bi数据集)。
|
归一化 |
初始精度 (%) |
扩展精度(%) |
综合精度(%) |
|
RGB柱状图匹配 |
95.00 |
87.50 |
91.67 |
|
Macenko等人 [21] |
90.00 |
81.25 |
86.11 |
|
不归一化 |
90.00 |
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

