
英语原文共 15 页,剩余内容已隐藏,支付完成后下载完整资料
Segnet: 一种用于图像分割的深度卷积编码-解码架构
Vijay Badrinarayanan, Alex Kendall , and Roberto Cipolla, Senior Member, IEEE
摘要
我们展示了一种新奇的有实践意义的深度全卷积神经网络结构,用于逐个像素的语义分割,并命名为SegNet.核心的可训练的分割引擎包含一个编码网络,和一个对应的解码网络,并跟随着一个像素级别的分类层.编码器网络的架构在拓扑上与VGG16网络中的13个卷积层相同.解码网络的角色是映射低分辨率的编码后的特征图到输入分辨率的特征图.具体地,解码器使用在相应编码器的最大合并步骤中计算的池化索引来执行非线性上采样.这消除了上采样的学习需要.上采样后的图是稀疏的,然后与可训练的滤波器卷积以产生密集的特征图.我们把我们提出的架构和广泛采用的FCN架构和众所周知的DeepLab-LargeFOV、DeconvNet架构做了比较,这种比较揭示了实现良好分割性能的内存与准确性的权衡。
SegNet的主要动机是场景理解应用.因此,它在设计的时候保证在预测期间,内存和计算时间上保证效率.在可训练参数的数量上和其他计算架构相比也显得更小,并且可以使用随机梯度下降进行端到端的训练.我们还在道路场景和SUN RGB-D室内场景分割任务中执行了SegNet和其他架构的受控基准测试.这些定量的评估表明,SegNet在和其他架构的比较上,提供了有竞争力的推断时间和最高效的推理内存.我们也提供了一个Caffe实现和一个web样例http://mi.eng.cam.ac.uk/projects/segnet/。
1 介绍
语义分割具有广泛的应用范围,从场景理解,推断对象之间的支持关系到自主驾驶.依靠低级别视觉线索的早期方法已经被流行的机器学习算法所取代.特别的,深度学习后来在手写数字识别、语音、整图分类以及图片中的检测上都取得了成功[VGG][GoogLeNet].现在图像分割领域也对这个方法很感兴趣[crfasrnn][parsent]等.然而,近来的很多方法的都尽力直接采用设计来图像分类的方法进行语义分割.结果虽然令人鼓舞,但是比较粗糙[deeplab].这主要是因为max-pooling和sub-sampling减少了特征图的分辨率.我们设计SegNet的动机就是来自于对于为了语义分割而从低分辨率的特征图到输入分辨率映射的需要.这种映射也必须产生一些特征用于精确地边界定位.
我们的架构,SegNet,设计的目的是作为一种高效的语义分割架构.它主要是由道路现场理解应用的动机,需要建模外观(道路,建筑物),形状(汽车,行人)的能力,并了解不同类别(如道路和侧面行走)之间的空间关系(上下文).在典型的道路场景中,大多数像素属于大型类,如道路,建筑物,因此网络必须产生平滑的分段.引擎还必须具有根据其形状来描绘对象的能力,尽管它们的尺寸很小.因此,在提取的图像表示中保留边界信息是重要的.从计算的角度来看,在推理过程中,网络需要保证在内存和计算时间两方面都是高效的.进行端到端的训练为了使用诸如随机梯度下降(SGD)之类的有效的权重更新技术来联合优化网络中所有权重的能力是一个额外的好处,因为它更容易重复.SegNet的设计源于需要符合这些标准.
SegNet中的编码网络和VGG16的卷积层是拓扑上相同的.我们移除了全连接层,这样可以使SegNet比其他许多近来的结构[FCN][DeconvNet][ParseNet][Decoupled]显著的小并且训练起来更容易.SegNet的关键部件是解码器网络,由一个对应于每个编码器的解码器层次组成.其中,解码器使用从相应的编码器接受的max-pooling indices来进行输入特征图的非线性upsampling.这个想法来自设计用于无监督功能学习的架构.在解码网络中重用max-pooling indics有多个实践好处:(1)它改进了边界划分(2)减少了实现端到端训练的参数数量(3)这种upsampling的形式可以仅需要少量的修改而合并到任何编码-解码形式的架构[FCN][crfasrnn].
这篇论文的一个主要贡献是,我们对Segnet解码技术和广泛使用的FCN的分析.这是为了传达在设计分割架构中的实际权衡.近来许多分割的深度架构使用相同的编码网络,例如VGG16,但是在解码网络的形式、训练和推理上是不同的.另一个常见的特点是,这些网络通常有亿级别的训练参数,从而导致端到端的训练很困难[DeconvNet].训练困难导致了多阶段的训练[FCN],或者添加一个与训练的网络结构如FCN[crfasrnn],或者用辅助支持,例如在推理阶段使用区域proposals[DeconvNet],或者使用分类和分割网络的不相交训练[Decoupled],或者用额外的数据进行与训练[Parsenet]或者全训练[crfasrnn].另外,性能提升后处理技术也受到欢迎.尽管这些因素都很好的提高了在voc上的性能,但是他们的定量结果难以解决实现良好性能所必需的关键设计因素.因此我们分析了被用在这些方法[FCN][DeconvNet]中的解码过程,并揭示了他们的优点和缺陷.
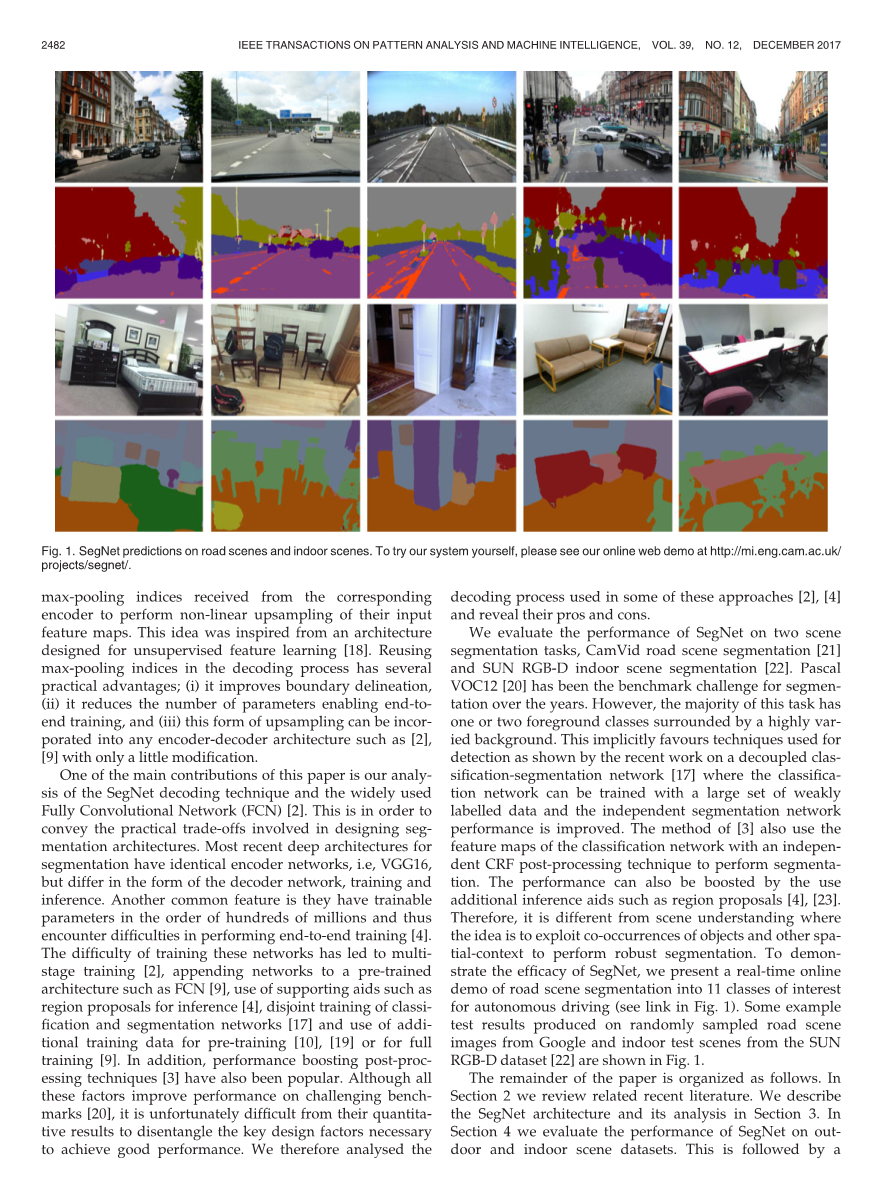
我们评估了SegNet在两种场景分割任务中的性能,分别是CamVid道路场景分割和SUN RGB-D室内场景分割.VOC12在过去很多年都有分割的居基准挑战.但是,这个任务的大部分都有一个或两个由高度多样的背景包围的前景类.这隐含地有利于用于检测的技术,如最近关于解耦分类分割网络的工作所示[Decoupled],其中分类网络可以用大量弱标签数据进行训练,并且独立分割网络性能得到改善.[deeplab]的方法还使用分类网络的特征图和独立的CRF后处理技术来执行分割.性能也可以通过额外的推理辅助来增强,例如区域proposals[DeconvNet][Edge Boxes].因此,因此,它与场景理解不同之处在于,其目的是利用对象的共同出现以及其他空间上下文来执行可靠的分割.为了证明SegNet的高效性,我们展示了一个实时的道路场景分割的在线demo,来分割11类的自主驾驶兴趣类(如图1所示).图1中展示了从Google中找的一些随机道路图片和SUNRGB-D中产生的一些随机室内测试场景图片的分割结果.
图1.Segnet 预测道路和室内场景。
论文的剩余部分组织如下.在Section 2我们回顾了近期的相关文献.在Section 3我们描述了SegNet架构和对它的分析.在Section 4我们评估了SegNet在室外和室内数据集上的性能.接下来是Section 5关于我们的方法的一般性讨论,指出未来的工作.Section 6是结论.
2 文献回顾
语义分割是一个十分活跃的研究课题,其中很大一部分作用是因为作为挑战的数据集[PASCALVOC][SUN RGB-D][KITTI].在深度学习到来之前,性能最好的方法大部分依赖于手工设计的特征来独立地分类像素.通常,将一块区域送入一个分类器例如Random Forest或者Boosting来预测中心像素的类概率.基于外观的特征或者sfM(不知道是什么)已经被发明用来进行CamVid道路场景理解的测试.后通过使用成对或更高阶的CRF来平滑来自分类器的每像素噪声预测(通常称为一元项)来提高精确度.最近的方法旨在通过尝试预测块中所有像素的标签,而不仅仅是中心像素来产生高质量的一元项.这改进了随机森林一元项的结果,但是薄结构化类被分类不佳.CamVid测试中性能最好的技术通过将对象检测输出与CRF框架中的分类器预测相结合来解决标签频率之间的不平衡.所有这些技术的结果表明需要改进的分类的特征.
自从NYU数据集的发布以来,室内RGBD像素级语义分割也得到欢迎.该数据集显示了深度通道改善分割的有用性.他们的方法使用诸如RGB-SIFT,depth-SIFT和像素位置的特征作为神经网络分类器的输入来预测像素一元项.然后使用CRF来光滑这个有噪音的一元项.使用更丰富的特征集进行改进,包括LBP和区域分割,以获得更高的准确性,然后是CRF.还要一些其他的方法,所有这些方法的共同属性是使用手工设计的特征来分类RGB或RGBD图像.
深层卷积神经网络对物体分类的成功最近引导研究人员利用其特征学习能力进行结构化预测问题,如分割.还尝试将设计用于对象分类的网络应用于分割,特别是通过在块中复制最深层特征以匹配图像尺寸.然而,所得到的分类是块状的.另一种方法是使用循环神经网络[RNN]合并了几个低分辨率预测来创建输入图像分辨率预测.这些技术已经是手工设计特征的改进,但是它们划定边界的能力差.
更新的深度结构[FCN][DeconvNet][CRFASRNN][Decoupled]特别设计用于分割,通过学习解码或将低分辨率图像表示映射到像素点预测,提升了最先进的技术水平.上边几个网络的编码网络是用来产生低分辨率便是,都是使用的VGG16分类网络结构(13个卷基层和3个全连接层).这些编码网络的权重在ImageNet上进行了特殊的预训练.解码器网络在这些架构之间不同,并且是负责为每个像素生成多维特征以进行分类的部分.
全卷积网络(FCN)架构中的每个解码器都学习对其输入特征图进行上采样,并将其与相应的编码器特征图组合,以产生到下一个解码器的输入。它是一种在编码器网络中具有大量可训练参数的架构(参数个数134M),但是非常小的解码器网络(参数个数0.5M).该网络的整体大小使得难以在相关任务上端到端地进行训练.因此,作者使用了阶段性的训练过程.这里,解码器网络中的每个解码器逐渐添加到现有的训练好的网络中.网络生长直到没有观察到进一步的性能提高.这种增长在三个解码器之后停止,因此忽略高分辨率特征图肯定会导致边缘信息的丢失[DeconvNet].除了训练的相关问题之外,解码器中重用编码器特征图的需求使其在测试时间内内存集约.我们更深入地研究这个网络,因为它是其他最新架构的核心[CRFASRNN][ParseNet].
通过使用循环神经网络(RNN)附加到FCN[CRFASRNN]并对其在大的数据集上[VOC][COCO]进行微调,FCN的预测性能进一步得到改善.在使用FCN的特征表征能力的同时,RNN层模仿CRF的尖锐边界划分能力.它们比FCN-8显示出显着的改进,但也表明当使用更多训练数据训练FCN-8时,这种差异减小.当与基于FCN-8的架构联合训练时,CRF-RNN的主要优点被揭示出来.联合训练有助于其他最近的结果.有趣的是,反卷积网络[DeconvNet]的性能明显优于FCN,但是以更复杂的训练和推理为代价.这提出了一个问题,即随着核心前馈分割引擎的改进,CRF-RNN的感知优势是否会减少.无论如何,CRF-RNN网络可以附加到任何深度分段架构,包括SegNet.
多尺度的深层架构也被广泛采用.它们有两种风格,(i)使用几个尺度的输入图像和相应的深度特征提取网络,以及(ii)组合来自单个深层结构的不同层的特征图[ParseNet].通常的想法是使用多尺度提取的特征来提供局部和全局上下文[zoom-out],并且早期编码层的使用特征图保留更高频率的细节,从而导致更尖锐的类边界.其中一些架构由于参数大小而难以训练.因此,与数据增加一起使用多阶段训练过程.推论过程由于特征提取的多个卷积路径使用也是复杂度比较高的.其他在他们的多尺度网络上附加了一个CRF,并共同训练他们.然而,这些在测试时间不是前馈的,需要优化才能确定MAP标签.
最近提出的几种最新的分割结构在推理时间上不是前馈的[DeconvNet][deeplab][Decoupled].它们需要通过CRF的MAP推理或推荐的区域proposals[DeconvNet]等辅助工具.我们认为通过使用CRF获得的感知性能提升是由于在其核心前馈分割引擎中缺乏良好的解码技术.另一方面,SegNet使用解码器获得准确的像素级别分类效果.
最近提出的反卷积网络[DeconvNet]及其半监督变体解耦网络[Decoupled]使用编码器特征图的最大位置(pooling index)在解码器网络中执行非线性上采样.这些架构的作者独立于SegNet(首次提交给CVPR 2015),提出了解码网络中的解码思想.然而,它们的编码器网络由VGG-16网络包括全连接,其包括其整个网络的约90%的参数.这使得他们的网络训练非常困难,因此需要更多的辅助工具,例如使用区域proposals来实施培训.此外,在推理阶段这些proposals被使用,这显着增加了推理时间.从基准的角度来看,这也使得在没有其他辅助帮助下难以评估其架构(编码器 -解码器网络)的性能.在这项工作中,我们丢弃VGG16编码器网络的全连接层,使我们能够使用SGD优化使用相关的训练集训练网络.另一种最近的方法[deeplab]显示了在不牺牲性能,显着减少参数数量的好处是能够减少内存消耗和改进推理时间.
我们的工作是由Ranzato等人提出的无监督特征学习架构的启发.这种架构用于无监督的预训练进行分类.然而,这种方法没有尝试使用深度编码器-解码器网络进行无监督的特征训练,因为它们在每个编码器训练之后丢弃解码器.在这里,SegNet与这些架构不同,因为深度编码器 - 解码器网络被联合训练用于监督学习任务,因此解码器是测试时间中网络的组成部分.
3 架构
架构如图2所示.
图2.解释Segnet结构。没有全连接层只有卷积层
编码器部分使用的是VGG16的前13层卷积网络,可以尝试使用Imagenet上的预训练.我们还可以丢弃完全连接的层,有利于在最深的编码器输出处保留较高分辨率的特征图.与其他最近的架构[FCN][DeconvNet]相比,这也减少了SegNet
全文共11362字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[12416],资料为PDF文档或Word文档,PDF文档可免费转换为Word
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。
您可能感兴趣的文章
- GIS矢量地图的鲁棒水印方案外文翻译资料
- 中国相似地理位置发达地区房价影响因素的差异——以西安高新区和沣渭新区为例外文翻译资料
- 集成数据在城市土地利用变化时空动态监测的应用——以印度金奈都市为例外文翻译资料
- 全球地表水及其长期变化的高分辨率制图外文翻译资料
- 造成沿海大型城市内涝灾害的主要因素识别——以中国广州为例外文翻译资料
- 基于SFPHD框架的中国快速城市化地区城市生态系统健康综合评价方法外文翻译资料
- 基于绿地演变的未来城市地表热岛强度的多情景模拟预测外文翻译资料
- 中国大陆272个城市地面和冠层城市热岛强度的长期趋势外文翻译资料
- 与孟加拉湾热带气旋有关的中国低纬度高原远距离降雨事件外文翻译资料
- 新丰江水库流域GPM IMERG降水产品评价及水文效用研究外文翻译资料

