
英语原文共 10 页
多尺度变换的目标检测
摘要
尺度问题是目标检测的核心问题。在本文中,我们开发了一个全新的 Scale-Transferrable Detection网络(STDN),用于检测图像中的多尺度对象。与以前的方法不同,以前的方法只是简单地结合来自不同网络深度的多个特征映射的对象预测,提出的网络具有嵌入式超分辨率层(本工作中称为尺度传输层/模块),可以显式地探索跨多个检测尺度的尺度间一致性本质。尺度转换模块天然适合基础网络,计算成本很低。该模块进一步与密集卷积网络(DenseNet)集成,生成one stage目标检测器。我们在PASCAL VOC 2007和MS COCO数据集上评估了我们提出的体系结构,STDN在可比的最先进的检测模型上获得了显著的改进。
1.简介
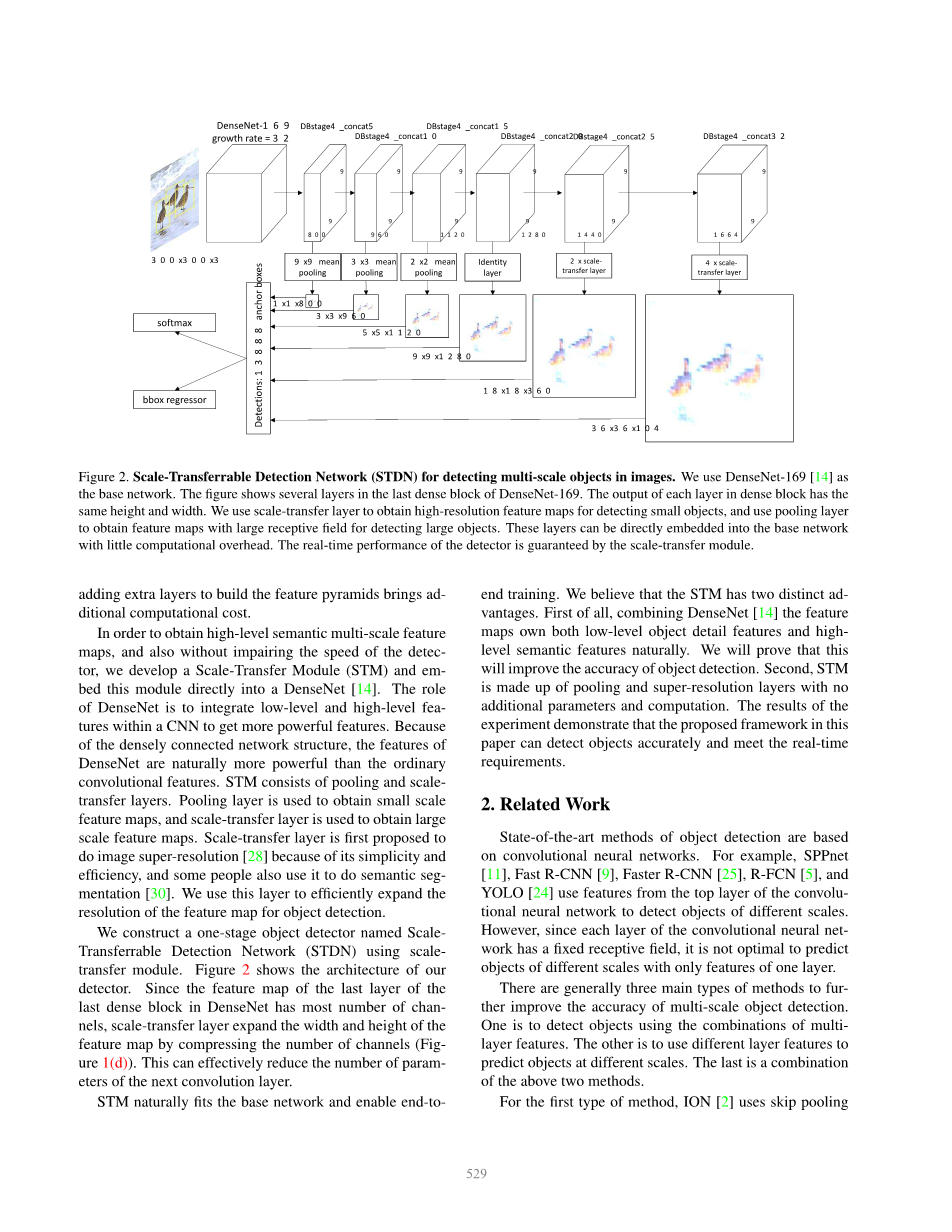
尺度问题是物体检测的核心。在为了检测不同尺度的物体,基本策略是使用图像金字塔来获得不同尺度的特征。但是,这将大大增加存储空间和计算复杂度,这将降低实时目标检测器的性能。近年来,卷积神经网络(CNN)在计算机视觉任务中取得了很大的成就,例如图像分类,语义分割目标检测。用卷积神经网络计算的特征代替人工设计的特征,大大提高了目标检测器的性能。Faster R-CNN使用由一层计算的卷积特征图来预测具有不同尺度和纵横比的候选区域(图1(a))。由于CNN中每一层的接受域都是固定的,所以在自然图像中,固定的接受域与不同尺度的物体之间存在着不一致。这可能会损害目标检测器性能。SSD和MS-CNN使用CNN内不同层的特征图来预测不同尺度的对象。浅层特征图具有用于检测小对象的小接受域,而深层特征图具有用于检测大对象的大接受域。然而,浅层特征的语义信息较少,这可能会影响小目标检测的性能。FPN,ZIP和DSSD在特征图上集成了各种尺度语义信息。如图1(b)所示,自顶向下的体系结构结合了高级语义特征图和低级语义特征图,从而在所有尺度上生成更多的语义特征图。但是,为了提高检测性能,必须仔细构造特征金字塔,并且添加额外的层来构建特征金字塔会带来额外的计算成本。为了获得高级语义多尺度特征图,同时又不影响检测器的速度,我们开发了一个尺度转换模块(STM),并将该模块直接嵌入到DenseNet中。DenseNet的作用是在CNN中集成低级和高级特征,以获得更强大的特征。由于密集连接的网络结构,DenseNet的特征自然比普通卷积特征更强大。STM由池化层和尺度转换层组成。池化层用于获取小尺度特征图,尺度转移层用于获取大尺度特征图。尺度转换层由于其简单、高效的特点,被提出用于图像超分辨率检测,也有人利用它来进行语义分割。本文利用该层有效地扩展了目标检测的特征图分辨率。本文构造了一个one-stage目标检测器名为ScaleTransferrable Detection Network (STDN)。图2显示了我们的检测器的体系结构。由于DenseNet中最后一个密集块的最后一层特征图通道数量最多,scale-transfer层通过压缩通道数量来扩展特征图的宽度和高度(图1(d))。这样可以有效地减少下一个卷积层的参数个数。STM自然适合基本网络,并支持端到端培训。我们认为STM有两个明显的优势。首先,结合DenseNet的特征映射,可以很自然地同时拥有低层对象细节特征和高层语义特征。我们将证明这将提高目标检测的准确性。其次,STM由池和超分辨率层组成,不需要额外的参数和计算。实验结果表明,本文提出的框架能够准确地检测目标,满足实时性要求。
2.相关工作
目前最先进的目标检测方法是基于卷积神经网络的。例如SPPnet、Fast R-CNN[9]、Faster R-CNN、R-FCN、YOLO等,利用卷积神经网络顶层的特征来检测不同尺度的对象。然而,由于卷积神经网络的每一层都有一个固定的接收域,仅用一层的特征来预测不同尺度的目标并不是最优的。进一步提高多尺度目标检测精度的方法主要有三种。一种是使用多层特征的组合来检测对象。另一种是使用不同的层特征来预测不同尺度的对象。最后是上述两种方法的结合。对于第一种方法,ION使用跳过池化在多个层提取信息,然后使用组合的特征检测对象。HyperNet集成了图像的深、中、浅特性,用于生成建议和检测对象。YOLOv2通过passthrough层将高分辨率的特征与低分辨率的特征连接起来,并在这个扩展的特征图上运行检测。这些方法的基本思想是通过结合低级和高级特征来增强特征的能力。对于第二种方法,SSD、MS-CNN和DSOD结合多个特征图的预测来处理不同大小的对象。例如,对于小对象,使用浅层特征,对于大对象,使用深特征。由于缺乏语义信息,浅层特征可能会影响小目标检测的性能。最后一种方法是同时使用上述两种方法。不同尺度的预测对象有多个预测层,每一个预测层的特征都是通过结合不同深度的特征得到的。FPN和TDM使用自顶向下的体系结构来构建高级语义特征图。DSSD使用沙漏结构来传递用于预测的上下文信息。这些方法需要添加额外的层来获得多尺度的特征,引入了不可忽视的代价。
3. Scale-Transferrable Detection Network
在本节中,我们首先介绍了基本网络,这是我们的特征提取网络组件。我们使用DenseNet作为基本网络。在DenseNet的每个密集块中,对于每一层,它的feature map都用作所有后续层的输入。密集块的最后一层的输出通道数最多,适合作为尺度转换层的输入,通过压缩通道数来扩展特征图的宽度和高度。然后描述了生成不同尺度特征图的尺度转换模块。接下来,我们描述了整个目标检测/位置预测网络体系结构和网络训练细节
3.1基础网络:DenseNet
采用DenseNet-169作为特征提取的基础网络,对ILSVRC CLSLOC数据集进行预处理。DenseNet是一个具有深度监管的网络。在DenseNet的每一个密集块中,每一层的输出都包含了之前所有层的输出,从而包含了输入图像的低层和高层特征,适合于对象检测。受DSOD的启发,我们将输入层(7times;7卷积层,stride = 2,然后是3times;3 max pooling层,stride = 2)替换为3times;3卷积层和1个2times;2均值pooling层。第一个卷积层的步长是2,其他的是1。三个卷积层的输出通道都是64。我们称这些层为“stem block”。表1详细描述了我们的网络体系结构。实验表明,这种简单的替代可以显著提高目标检测的准确性(消融研究见表3)。一种解释是原始DenseNet-169中的输入层由于连续两次向下采样而丢失了很多信息。这将损害对象检测的性能,特别是对小对象。
3.2高效率尺度转移模块
尺度问题是目标检测的核心问题。将不同分辨率的多地物图预测结果相结合,有利于多尺度目标的检测。但是,如图2所示,在DenseNet的最后一个密集块中,除了通道的数量外,所有层的输出都具有相同的宽度和高度。例如,当输入图像为300times;300时,DenseNet-169的最后一个密集块尺寸为9times;9。一种简单的方法是直接使用类似于SSD的低分辨率地物图进行预测。但是,低层特征图缺乏对目标的语义信息,这可能导致对目标检测的性能较低。Ablation研究见表3。为了得到不同分辨率的特征图,受超分辨率方法的启发,我们开发了一个称为尺度转换模块。尺度转换模块非常高效,可以直接嵌入到DenseNet的密集块中。为了获得较强的语义特征映射,我们利用DenseNet的网络结构,通过concat操作将底层特征直接转移到网络的顶层。网络顶部的特征图既有低层的细节信息,又有高层的语义信息,从而提高了目标定位和分类的性能。我们从DenseNet的最后一个密集块中得到了不同尺度的特征图。在尺度转换模块中,我们使用平均池层来获得低分辨率的特征图。对于高分辨率的地形图,我们使用一种称为尺度转换层的技术。假设尺度传递层输入张量的维数为Htimes;Wtimes;C·r2,其中r为上采样因子。尺度转移层是元素周期性重排的一种操作。如图3所示,scale-transfer层通过压缩特征图中的通道数来扩展宽度和高度。尺度转移层可以有效地减少DenseNet稠密块最后一层的信道数,减少下一卷积预测层的参数和计算量。这提高了探测器的速度。利用DenseNet的优点,特征图具有低层细节信息和高层语义信息。实验结果表明,我们的尺度可转移检测器在目标检测的精度和速度上都有很好的表现(表5)。
3.3对象本地化模块
可标度转移检测网络(STDN)由一个基本网络和两个任务特定的预测子网络组成。基本网络的作用是做特征提取。第一个子网用于对象分类,第二个子网用于包围盒位置回归。我们已经在上面详细描述了基本网络。接下来我们将详细介绍两个预测子网络和训练目标。
3.3.1Anchor Boxes
我们将一组默认的anchor boxes与我们的scale-transfer模块获得的每个feature map关联起来。anchor boxes的尺寸与SSD相同。在DSSD之后,我们在每个预测层使用[1.6、2.0、3.0]纵横比。anchor与任何高于阈值(0.5)的相交过并(IoU)的地面真相匹配。其余的anchor作为背景。在匹配步骤之后,大多数默认anchor boxes锚框都是负数(没有匹配)。我们使用硬负极挖掘,所以负极和正极的比例最多是3:1
3.3.2分类子网
分类子网的作用是预测属于一个类别的每个anchor的概率。它包含一个1times;1卷积层和两个3times;3卷积层。每个卷积层前面都有一个batchnorm层和一个relu层。最后一个卷积层有K A滤波器,其中K是对象类的数量,A是每个空间位置的anchor的数量。分类损失是多个类置信度的的softmax 损失。
3.3.3 Box Regression Subnet
这个子网的目的是将每个anchor box的偏移量返回到匹配的ground-truth对象。除了最后一个卷积层有4A滤波器外,box回归子网的结构与分类子网相同。光滑L1损失用于定位损失,bounding boxes损失仅用于阳性样本
3.3.4 Training Settings
我们的检测器基于MXNet框架。我们所有的模型都训练与SGD解决方案的NVIDIA TITAN Xp GPU。我们采用几乎与SSD相同的训练策略,包括一个随机扩展数据增强技巧,这有助于检测小对象。
4.实验
4.1实验设置和实施
我们在PASCAL VOC[6]和MS COCO数据集上评估了我们的方法,这两个数据集分别有20和80个对象类别。对于评估,我们使用标准平均精度(mAP)评分。对于PASCAL VOC,我们使用IoU阈值0.5报告mAP评分。对于COCO,我们使用标准的COCO度量。对于在PASCAL VOC上输入300times;300的模型,由于GPU内存的限制,我们对模型进行了小批量80的训练。在最初的500个时代,我们的学习率从0.001开始。我们在600个epoch将其降低到10 - 4,在700个世代将其降低到10 - 5。我们将这个训练有素的模型作为STDN321和STDN513在PASCAL VOC上的预训练模型。
4.2PASCALVOC2007
表2显示了我们对PASCAL VOC2007测试检测的结果。其中,SSD只使用不同深度的feature map进行预测,而没有融合低层和高层的feature。我们用它作为基线。DSSD是SSD的升级版本,它将SSD的基本网络从VGG替换为一个深剩余网络。此外,DSSD添加了额外的层来融合不同深度的特性。这将产生具有强大语义信息的特性。通过添加这些操作,DSSD321和DSSD513分别比SSD300和SSD512好约1.1%-2%。虽然与SSD相比,DSSD提高了精度,但是由于基网极深和特征融合效率低下,使得目标检测器的速度受到了很大的影响。速度和精度的比较将在表5中讨论。令人兴奋的是,STDN在DenseNet中嵌入了高效的尺度传输模块,提高了目标检测的精度,几乎不增加运行时间。对于相同大小的输入图像,STDN300的精度比SSD300高0.6%。STDN513比SSD512高1.4%。这些结果证明了我们方法的有效性。我们还比较了STDN和DSSD的结果。STDN321比DSSD321高0.7%,但STDN513比DSSD513低0.6%。我们认为原因可能是残差- 101比DenseNet169 (42M vs 14M)具有更多的网络参数,因此具有更大的容量,然而,这同时降低了目标探测器的速度
4.3VOC2007的Ablation研究
为了验证各组分在STDN中的有效性,我们在VOC2007上设计了ablation实验。结果如表3所示。
4.3.1尺度转移模块(STM)的影响
在表3中,DenseNet-169 SSD表明,我们使用DenseNet作为提取特征的基础网络,使用不同深度的特征图进行目标检测。这类似于SSD方法,但是将基本网络从VGG切换到DenseNet-169。DenseNet-169 STM表明,我们使用scale-transfer模块获取多尺度特征图用于目标检测。在相同的基础网络下,STM为76.6% mAP,比SSD高2.8%。验证了STM方法的有效性
4.3.2stem block的影响
表3第三行和第四行表明,stem block可以显著提高目标检测精度,从76.6%提高到78.1%。我们认为原因是DenseNet-169的原始输入层有两个连续的下行采样操作(conv和stride 2的max pooling),导致信息丢失过多,影响了检测器的性能。
4.3.3密集卷积网络的影响
DenseNet是一个具有深度监控的网络,它以一种前馈的方式将每一层连接到每一层。我们比较了深度监督网络和非深度监督网络的性能。我们在比较测试中使用了Inceptionv3,它也在ILSVRC cl - loc数据集上进行了预训练。我们在inc
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

