
英语原文共 16 页
FusionGAN:用于红外和可见图像融合的生成对抗网络
摘要
红外图像可以根据热辐射的差异区分目标和背景,这在所有日/夜时和所有天气条件下都能很好地工作。相比之下,可见图像可以以与人类视觉系统一致的方式提供具有高空间分辨率和清晰度的纹理细节。本文提出了一种利用生成对抗网络融合这两类信息的新方法,称为FusionGAN。我们的方法在生成器和判决器之间建立对抗性游戏,其中生成器旨在生成具有主要红外强度以及附加可见梯度的融合图像,并且判决器旨在迫使融合图像在可见图像中存在更多细节。这使得最终融合图像能够同时将热辐射保持在红外图像中并且将纹理保持在可见图像中。此外,我们的FusionGAN是一种端到端模型,避免像传统方法那样手动设计复杂的活动级别测量和融合规则。公共数据集上的实验证明了我们的战略优于现有技术,我们的结果看起来像锐化的红外图像,具有清晰的突出目标和丰富的细节。此外,我们还推广我们的FusionGAN融合不同分辨率的图像,比如低分辨率的红外图像和高分辨率的可见图像。大量结果表明,我们的策略可以生成清晰、干净的融合图像,不会受到红外信息上采样引起的噪声影响。
关键字:图像融合;红外图像;可见光图像;生成对抗网络;深度学习
概论
图像融合是一种增强技术,旨在组合由不同类型的传感器获得的图像,以生成稳健或信息丰富的图像,可以促进后续处理或帮助决策[1,2]。特别地,诸如热红外和可见图像的多传感器数据已被用于增强人类视觉感知,物体检测和目标识别方面的性能[3]。例如,红外图像捕获热辐射,而可见图像捕获反射光。这两种类型的图像可以提供具有互补属性的不同方面的场景信息,并且它们也是几乎所有对象中固有的[4]。
图像融合问题已经用不同的方案开发,包括多尺度变换[5-7],稀疏表示[8,9],神经网络 [10,11],子空间[12,13]和基于显着性[14,15]方法,混合模型[16,17]和其他方法[18,19]。然而,主要的融合框架涉及三个关键组件,包括图像变换,活动水平测量和融合规则设计。现有方法通常在融合过程期间对不同的源图像使用相同的变换或表示。然而,它可能不适合红外和可见图像,因为红外图像中的热辐射和可见图像中的外观是两种不同现象的表现。此外,大多数现有方法中的活动水平测量和融合规则是以手动方式设计的,并且它们变得越来越复杂,具有实施难度和计算成本的局限性[21]。
为克服上述问题,本文从基于生成对抗网络(FusionGAN)的新视角提出了一种红外和可见光图像融合方法,该方法将融合作为保持红外热辐射信息和保持红外热辐射信息的对抗性游戏。可见外观纹理信息。更具体地说,它可以被视为生成器和判决器之间的最小极大问题。这使我们的融合图像能够同时保持红外图像中的热辐射和可见图像中的纹理细节。此外,生成对抗网络(GAN)的端到端属性可以避免手动设计复杂的活动级别测量和融合规则。
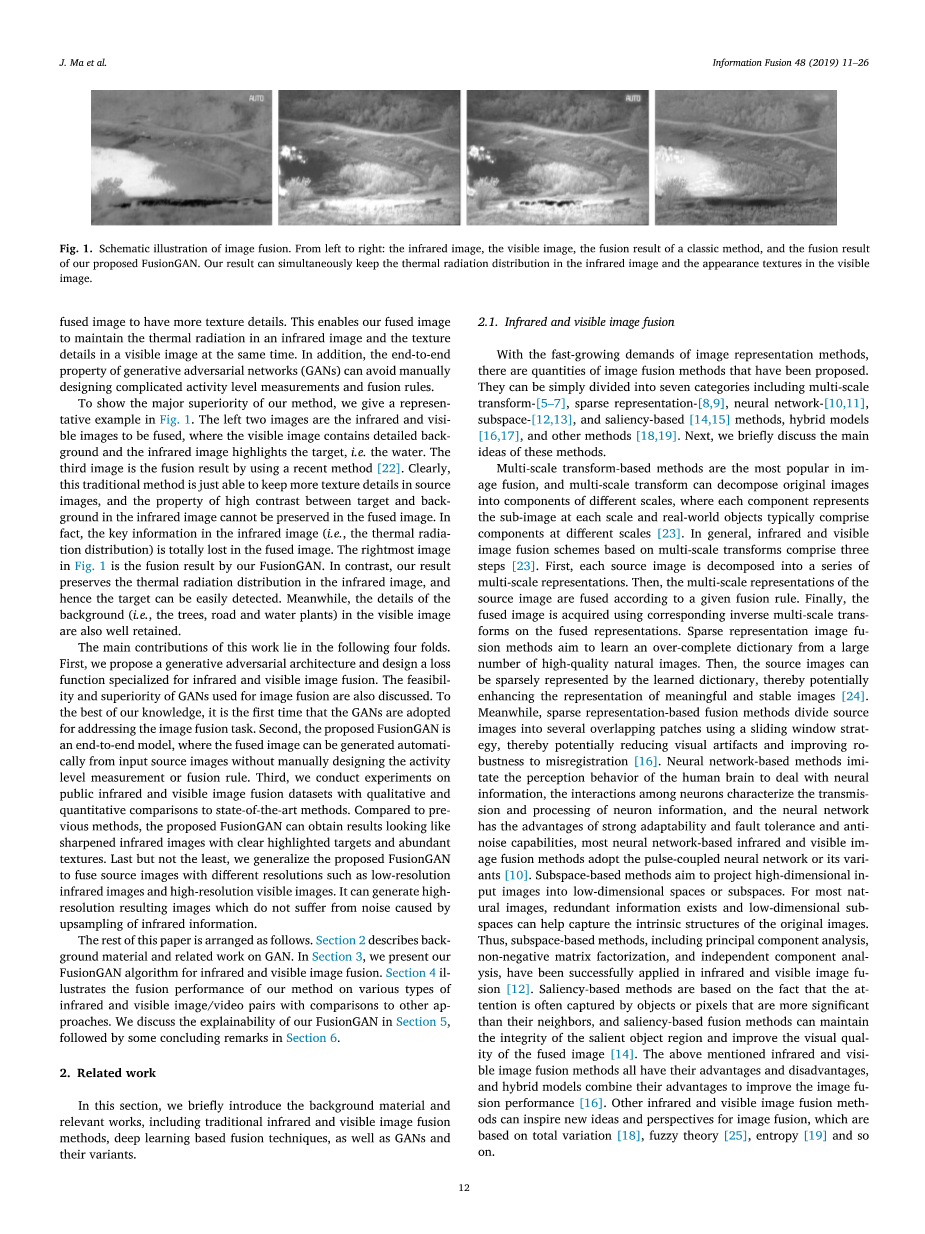
为了显示我们方法的主要优势,我们在图1中给出了一个代表性的例子。左边的两个图像是要融合的红外和可见图像,其中可见图像包含详细的背景,红外图像突出显示目标,即水。第三个图像是使用最近的方法[22]的融合结果。显然,这种传统方法只能在源图像中保留更多的纹理细节,并且在融合图像中不能保留红外图像中目标和背景之间高对比度的特性。实际上,红外图像中的关键信息(即热辐射分布)在融合图像中完全丢失。图1中最右边的图像是我们的FusionGAN的融合结果。相反,我们的结果保留了红外图像中的热辐射分布,因此可以容易地检测目标。同时,还可以很好地保留可见图像中的背景(即树木,道路和水草)的细节。
这项工作的主要贡献在于以下四个方面。首先,我们提出了一种生成对抗体系结构,并设计了一种专门用于红外和可见图像融合的损失函数。还讨论了用于图像融合的GAN的可行性和优越性。据我们所知,这是第一次采用GAN来解决图像融合任务。其次,所提出的FusionGAN是端到端模型,其中融合图像可以从输入源图像自动生成,而无需手动设计活动水平测量或融合规则。第三,我们对公共红外和可见图像融合数据集进行实验,并对最先进的方法进行定性和定量比较。与以前的方法相比,所提出的FusionGAN可以获得看起来像锐化的红外图像的结果,具有清晰的突出显示的目标和丰富的纹理。最后但并非最不重要,我们概括了所提出的FusionGAN融合不同分辨率的源图像,如低分辨率红外图像和高分辨率可见图像。它可以产生高分辨率的结果图像,其不受由红外信息的上采样引起的噪声的影响。
本文的其余部分安排如下。第2节描述了GAN的背景材料和相关工作。在第3节中,我们介绍了用于红外和可见图像融合的FusionGAN算法。第4节说明了我们的方法在各种类型的红外和可见图像/视频对上的融合性能,并与其他方法进行了比较。我们在第5节中讨论了FusionGAN的可解释性,然后是第6节中的一些结束语。
相关工作
在本节中,我们将简要介绍背景材料和相关工作,包括传统的红外和可见图像融合方法,基于深度学习的融合技术,以及GAN及其变体
红外与可见光图像融合
随着图像表示方法的快速增长的需求,已经提出了大量的图像融合方法。它们可以简单地分为七类,包括多尺度变换[5-7],稀疏表示 [8,9],神经网络 [10,11],子空间 [12,13]和基于显著性的 [14,15]方法,混合模型[16,17]和其他方法[18,19]。接下来,我们简要讨论这些方法的主要思想。
基于多尺度变换的方法在图像融合中是最流行的,并且多尺度变换可以将原始图像分解成不同尺度的分量,其中每个分量表示每个尺度的子图像,并且现实世界对象通常包括在不同的尺度[23]。通常,基于多尺度变换的红外和可见光图像融合方案包括三个步骤[23]。首先,将每个源图像分解为一系列多尺度表示。然后,根据给定的融合规则融合源图像的多尺度表示。最后,使用融合表示上的对应逆多尺度变换来获取融合图像。稀疏表示图像融合方法旨在从大量高质量自然图像中学习过度完整的字典。然后,源图像可以由学习字典稀疏地表示,从而可能增强有意义和稳定图像的表示[24]。同时,基于稀疏表示的融合方法使用滑动窗口策略将源图像划分为若干重叠的补丁,从而可能减少视觉伪像并提高对重合失调的鲁棒性[16]。基于神经网络的方法模仿人脑的感知行为来处理神经信息,神经元之间的相互作用表征神经元信息的传递和处理,神经网络具有强适应性和容错性以及抗噪能力的优点,大多数基于神经网络的红外和可见光图像融合方法采用脉冲耦合神经网络或其变体[10]。基于子空间的方法旨在将高维输入图像投影到低维空间或子空间中。对于大多数自然图像,存在冗余信息,并且低维子空间可以帮助捕获原始图像的内在结构。因此,基于子空间的方法,包括主成分分析,非负矩阵分解和独立分量分析,已成功应用于红外和可见光图像融合[12]。基于显着性的方法基于以下事实:注意力通常由比其邻居更重要的对象或像素捕获,并且基于显着性的融合方法可以保持显着对象区域的完整性并且改善融合的视觉质量。图像[14]。上述红外和可见光图像融合方法各有优缺点,混合模型结合其优点,提高了图像融合性能[16]。其他红外和可见图像融合方法可以激发图像融合的新思路和新观点,它们基于总变差[18],模糊理论[25],熵[19]等。
基于深度学习图像融合
近年来,由于其强大的图像特征提取能力,深度学习也已成功应用于图像融合。在多焦点图像融合中,刘等人[26]训练深度卷积神经网络(CNN)联合生成活动水平测量和融合规则,他们还应用他们的模型融合红外和可见图像[27]。在多模态图像融合中,钟等人[28]提出了一种基于CNN的联合图像融合和超分辨率方法。此外,刘等人[29]引入了用于图像融合的卷积稀疏表示,其中反卷积网络旨在构建层的层次结构,并且每个层由编码器和解码器组成。在遥感图像融合中,Masi等人[30]提出了一种有效的三层结构来解决pansharpening问题,其中输入通过添加几个非线性辐射指数图来增强,以促进融合性能。
现有的基于深度学习的图像融合技术通常依赖于CNN模型,该模型具有事先应该提供基本事实的关键先决条件。对于多焦点图像融合和pansharpening问题,基本事实被很好地定义,例如,没有模糊区域的清晰图像或具有与相应的全色图像相同分辨率的多光谱图像。然而,在红外和可见图像融合的任务中,定义融合图像的标准是不现实的,因此,不考虑建立基本事实。在此基础上,现有的红外和可见图像融合技术不是学习需要地面真实融合图像的端到端模型,而是学习深层模型来确定源图像中每个斑块的模糊程度,然后相应地计算权重图以生成最终的融合图像[27]。在本文中,我们在GAN的框架中制定了融合问题,它没有遇到上述问题。
生成对抗网络及其变体
GAN是通过对抗过程估计生成模型的流行框架,深度卷积GAN(DCGAN)成功地将一类CNN引入GAN,而最小二乘生成对抗网络(LSGAN)克服了常规GAN中消失的梯度问题,在学习过程中更加稳定。接下来,我们将简要介绍上述三种相关技术。
2.3.1.生成对抗网络
Goodfellow等人[31]首先提出了GAN的概念,它在深度学习领域引起了广泛的关注。GAN基于minimax双人游戏,它可以提供一种简单而有效的方法来估计目标分布并生成新样本。GAN框架由两个对抗模型组成:生成模型G和判别模型D.生成模型G可以捕获数据分布,并且判别模型D可以估计样本来自训练数据而不是G的概率。更具体地说,GAN在判决器和生成器之间建立对抗性游戏,生成器将先前分布为P z的噪声作为输入并尝试生成不同的样本以欺骗判决器,并且判决器旨在确定样本是否是 从模型分布或数据分布,最终生成器生成不能被判决器区分的样本。在数学上,生成模型G旨在生成样本,其分布(PG)试图近似实际训练数据的分布(Pdata),G和D如下所示进行极小极大双人游戏:
但是,PG无法明确表示,D在训练期间必须与G很好地同步。因此,常规GAN是不稳定的,并且很难通过常规GAN训练良好的模型。
2.3.2.深度卷积GANs
Radrord等人首次提出了深度卷积GAN(DCGAN)技术[32]。DCGAN首次成功引入了CNN,这可以弥合CNN用于监督学习和GAN用于无监督学习之间的差距。由于传统的GAN不稳定以培养良好的模型,因此应该适当地设计CNN的架构以使传统的GAN更稳定,并且与传统的CNN相比主要有五个不同。首先,在生成器和判决器中都不使用池化层。相反,在判决器中应用跨步卷积来学习其自己的空间下采样,并且在生成器中使用分数跨度卷积来实现上采样。其次,将伪技术化层引入生成器和判决器中。由于不良的初始化总是会产生很多训练问题,因此伪技术化层能够解决这些问题并避免在更深层次的模型中消失梯度。第三,在更深的模型中移除完全连接的层。第四,除了最后一个激活层之外,生成器中的所有激活层都是整流线性单元(ReLU),最后一层是tanh激活。最后但并非最不重要的是,判决器中的所有激活层都是leacky ReLU激活。因此,训练过程变得更加稳定,并且可以提高生成结果的质量。
2.3.3.最小二乘GANs
尽管GAN取得了巨大成功,但仍有两个关键问题需要解决。首先是如何提高生成图像的质量。近年来,已经提出许多工作来解决这个问题,例如DCGAN。二是如何提高培训过程的稳定性。通过探索GAN的目标函数,已经提出了许多工作来解决这个问题,例如Wasserstein GANs(WGANs)[33],它比常规GAN收敛得慢得多[34]。另外,常规GAN对判决器采用S形交叉熵损失函数,这可能导致学习过程中的梯度消失问题。为克服上述两个问题,毛等人[34]提出了最小二乘生成对抗网络(LSGAN),它采用最小二乘损失函数作为判决器,LSGAN的目标函数定义如下
其中编码方案用于判决器和生成器,a和b分别表示伪数据和实数据的标签,c表示生成器希望判决器相信伪数据的值。有两种方法可以确定方程式中a,b和c的在Eq(2)。第一种是设置b - c = 1和b - a = 2,从而最小化Eq(2)使数据Pdata PG和PG之间的Pearson X^2最小化。第二个是设置c = b,它可以使生成器生成的样本尽可能真实。上面提到的两种方法通常会得到类似的性能。
在LSGAN中,惩罚位于决策边界很长的样本会使生成器生成的样本靠近决策边界并生成更多的梯度。因此,LSGAN比常规GAN具有两个优点。一方面,LSGAN可以生成比普通GAN更高质量的图像。另一方面,LSGAN在训练过程中比常规GAN执行更稳定。
方法
本节中,我们描述了所提出的用于红外和红外的FusionGAN可见图像融合。我们首先用GAN布置问题公式,然后讨论生成器和判决器的网络架构。最后,我们提供了网络培训的一些细节。
问题描述
为了同时保持红外图像的热辐射信息和可见图像的丰富纹理信息,我们从一个新的角度提出了一种新的融合策略。我们将红外和可见图像融合问题表示为对抗性问题,如图2(a)中示意性所示。开始时,我们在通道维度中连接红外图像Ir和可见图像Iv。然后,将连接的图像馈送到生成器中,并且生成器的输出是融合图像
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

