
英语原文共 7 页,剩余内容已隐藏,支付完成后下载完整资料
使用HMM语音识别系统对吸烟者和非吸烟者的语音进行比较
Hassan Satori1,2·Ouissam Zealouk1·Khalid Satori1·Fatima ElHaoussi2
文章历史:
2016年10月24日收到
2017年7月17日接受
2017年8月12日发布于施普林格
摘 要
自动语音识别技术是一种允许计算机实时将口语单词转录成可读文本的技术。本文设计了一个基于隐马尔可夫模型(HMM)的自动语音识别系统通过说话人的语音来检测说话人的身份。本次研究以阿马齐格语为研究对象,对使用阿马齐格语言的正常人与吸烟者的声音进行比较。为了实现这一目标,我们进行了两个实验,第一个实验是测试语音识别系统在设置不同参数下对非吸烟者的性能,第二个实验是测试语音识别系统关于吸烟者和演讲者的判断。本系统使用的语料库收集自两组说话者,非吸烟者和吸烟者是母语为莫罗坎塔利特的说话者,年龄在25到55岁之间。我们的实验结果表明,当观察到的识别率低于50%时,我们可以利用我们的系统对吸烟者做出诊断,并确认说话者是吸烟者。
关键字:自动语音识别系统,吸烟者效应,语音诊断,阿马齐格语言,隐马尔科夫模型,Sphinx4,GMM
- 介绍
自动语音识别(ASR)是一种计算机技术,它允许软件来解释说明一个自然的人类语言,它允许系统提取语音信号中包含的口头信息。该技术将计算机方法广泛应用于信号处理和人工智能领域。我们可以想象的应用程序有很多:例如帮助残疾人、机器语音控制、预订机票、学习其他语言等等。2014年Satori和Elhaoussi的作者利用CMU Sphinx工具开发了一个独立于扬声器的自动阿马齐格语音识别系统。该系统基于HMM,旨在识别阿马齐格语言的字母和数字。该系统使用16GMMs实现了89%的性能。Kimutai 等人在2013年利用CMU Sphinx工具建立一个语音识别系统,用来识别斯瓦希里语。该系统被训练识别40个斯瓦希里语单词。系统性能约为53%。Shaukat等人在2016年开发乌尔都语孤立词语音识别系统。该系统同样使用CMU sphinx引擎实现,系统经过训练可以识别250个单词。
在另一项研究中,研究人员开发了ASR系统,将语音混乱的人的语音信号转录成等价的文本。默罕默德等人在2011研究了六种声音障碍的发声困难患者的语音识别系统。在混乱组中系统的识别精度在56到82.50%之间,在正常测试的那一组的识别精度为100%。
在本次的这项工作中,我们设计研究了一个ASR系统,能够区分使用阿马齐格数字语音的吸烟者和不吸烟者的声音。我们使用由50名塔利菲特摩洛哥语使用者和另外10名吸烟的塔利菲特摩洛哥语使用者组成的语料库来训练我们的系统。
本文的其余部分组成如下:第二部分介绍了吸烟对人体声音的影响。第三部分介绍了我们设计的语音识别系统。第四部分着重介绍了对隐马尔可夫模型的描述。第五部分给出了对阿马齐格语言的概述。第六部分显示了这项工作所用的所有技术和方法。最后,第七部分介绍了实验结果的大概内容。最后,我们再以一个结论结束本文。
2.吸烟对声音的影响
吸烟对我们的喉部有负面影响。吸烟刺激并且会使我们的声带干燥,导致声带肿胀,使声带不能正常工作。Mckeating等人在1988年发现吸烟带来的影响会引起我们声音的音量、音高和音质的变化。作者在(Gonzalez和Capri 2014)和其中的参考文献表明,短时间的吸烟习惯,如果少于十年,对语音参数,例如基频,也会有明显的影响。Verdonckde Leeuw和Mahieu在2004年发现每天吸烟的数量对这些参数在基频、音高、振幅等方面表现出线性影响。
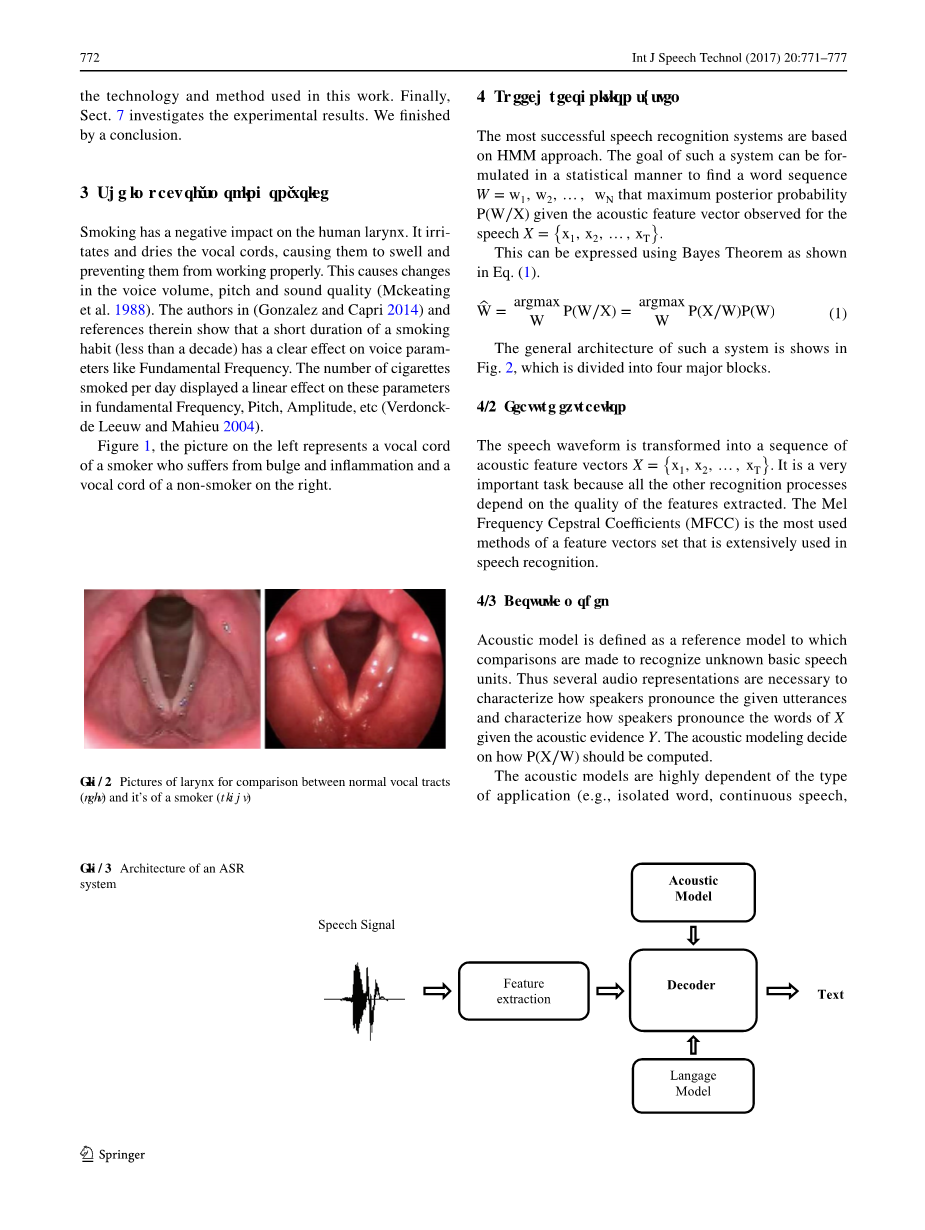
图1,右边的图片是一个患有鼓包和炎症的吸烟者的声带,左边的图片是一个不吸烟者的声带。
图1 喉的图片,比较正常的声道(左边)和吸烟者的声道(右边)
3.语音识别系统
目前来说,最成功的语音识别系统是基于隐马尔可夫模型方法的。这样一个系统的目标是以统计的方式来表达的,即通过找到一个单词序列W= w1, w2, hellip; , wN,采用最大后验概率P(W∕X),再采用观察到的语音特征向量 X={x1,x2, ... ,xT}。
这可以用贝叶斯定理来表示,如公式(1)所示。
(1)
该系统的总体架构如图2所示,主要分为四个模块,功能提取模块,声学模型模块,译码器模块和语言模型模块。
声学模型
语音信号
提取
功能
译码器
语言模型
图2 ASR系统的结构
3.1 特征提取
将语音波形转换成一系列声学特征向量的等值X ={x1, x2, hellip;, xT }。这是一个非常重要的任务,因为所有其他的语音识别过程都依赖于特征提取的质量。Mel频率倒谱系数(MFCC)是语音识别中应用最广泛的特征向量集方法。
3.2 声学模型
声学模型被定义为一个参考模型,是一个通过比较来识别未知的基本语音单元。因此,在给定的声学证据X的情况下,要确定说话者如何发出给定的话语,以及说话者如何发出W的单词,必须采用若干种音频表征方法。声学建模决定采用何种方式计算P(X∕W)。
声学模型高度依赖于应用程序的类型(例如:孤立词,连续言语,命令,等等)。一般来说,通过制定几个约束条件使得声学模型在计算上是可能的。
3.3 语言模型
在译码阶段,语言模型与声学模型同样重要。在自动语音识别系统中,解码器使用的主要语言模型是统计单字母、双字母或三字母模型。
3.4 译码器
译码器是语音识别系统中执行最重要任务的主要模块。它从特征提取模块中读取特征,并借助声学模型和语言模型将这些数据耦合起来。最后,再执行搜索从而确定最有可能由一系列观察结果表示的单词序列。
- 隐马尔可夫模型
隐马尔可夫模型(HMM)是语音识别建模中最常用的机器学习方法。这个模型是一个有限状态的集合,其中每个集合都与一个概率分布相关联。状态之间的转换由一组称为转换概率的概率控制。马尔可夫模型是将简单概念抽象成相对容易计算的形式的极好方法。通常将隐马尔可夫模型用于声音识别的数据压缩。在图3中给出了5种状态下的隐马尔可夫模型拓扑结构。
X1
1
2
3
4
图3五种状态的HMM拓扑结构
- 阿马齐格语言
阿马齐格语是一组哈密特-闪米特语,分为南北两部分。他们从摩洛哥到埃及,经过阿尔及利亚,突尼斯、利比亚、尼日尔和马里,一共有三十个地方。阿马齐格现在有自己的文字系统,其中一个保留了Touareg: Tifinaghe。
在摩洛哥,大约有28%的阿马齐格语使用者,根据地区和社区的不同,分为三个不同的主要地区:北部地区使用Tarifit语,中部和东南部使用Tamazight语,南部地区使用Tachelhit语。
自2003年起,Tifinaghe-IRCAM已成为摩洛哥官方的阿马齐格图形系统。该系统包含阿马齐格语言中允许的音节有:V, CV, VC, CVC, C, CC和CCC,其中V表示元音,而C表示辅音(Ridouane 2003)。在这项研究中,我们对Amazigh数字的语音识别感兴趣。表1显示了在我们的系统中使用的前10位阿马齐格数字的描述。
表1包含英语、阿拉伯语和阿马齐格字母转录的前十位
- 阿马齐格语音识别系统
在这项工作中,系统使用从两组说话者、非吸烟者和吸烟者收集的语音来比较他们的语音质量和使用ASR的技术表现。在此基础上,利用Sphinx4平台实现了一种适用于阿马齐格语言的小词汇量独立孤立语音识别器。不同的训练和测试参数,例如每个模型的状态数,高斯混合的数量等,被用来识别最佳组合,最终可以用来设计一个能够区分吸烟者和非吸烟者声音的ASR系统。
-
- 语音语料库
为了制作一个鲁棒的独立于扬声器的连续自动阿马齐格语音识别器,需要一套丰富和平衡的语音记录。本研究使用的语音语料库收集自50位精选的摩洛哥塔利菲特母语演讲者。演讲者被邀请从0到9依次发出10个阿马齐格数字,每个数字说10次。因此,这个语料库由5000个令牌组成。每一个阿马齐格数字都被记录下来并显示出来,以确保整个单词都包含在语音信号其中。发音错误的话语会被忽略,只有纠正的话语才会保存在数据库中。所有的语音样本都是使用wavesurfer开源软件录制的。并特别注意消除背景噪声。对于这项工作,采样率设置为16 kHz,分辨率为16位,语料库技术参数详见表2。一个扬声器的录音被保存为一个”.wav“文件,有时多达四个“.wav”文件取决于说话者完成录音所花费的会话数。此外,准备好的音频文件被分成两个独立的集,用于训练和测试。注意避免让某一位发言者参加两组会议,具体情况见表3。
表2语料库技术参数
|
参数 |
价值 |
||
|
采样率 比特数 Wav格式 语料库 口音 合计小时的培训 |
16赫兹 16位 Mono, wav 10 Amazigh-digits 摩洛哥Tarifit柏柏尔人 0.59333 |
||
表3语料库特征
|
用于培训的演讲者数量 |
用于测试的扬声器数量 |
||
|
不吸烟的烟民 吸烟者 总数 |
30 - 30 |
10 10 20 |
|
-
- 字典
字典为语言模型中每个现有的单词提供发音,并包括我们想要训练的单词,以及它们的抄写。同时,它包含用括号标记的单词的替代转录为(1)。发音词典可以看作是语言模型和声学模型之间的中介。我们的字典包含了前十个阿马齐格数字的符号表示。表4显示了用于训练我们的系统的发音字典。
表4培训中使用的语音词典列表
-
- 培训
训练声学模型需要从训练语音文件中计算出一组特征文件,每个特征文件对应训练语料库中的每个记录。每个记录被转换成一个由最常用的mel -频率倒谱系数(MFCCs)组成的特征向量序列。在训练过程中,使用Baum-Welch算法估计转移概率。该声学模型采用2到32高斯混合分布的连续状态概率密度进行训练。培训使用的声音来自30名不吸烟的塔利菲特摩洛哥语使用者。图4中显示了系统输出和训练程序所需的配置文件。
Amdigits
电话和填写文件
培训抄写和fileids文件
测试转录和fileids文件
配置文件
Wav文件
字典和lm.DMP文件
培训文件
测试文件
图4 ASR系统架构和必要的配置文件
- 实验结果
这项工作的实验是有两组演讲者,分为非吸烟者和吸烟者,他们使用小词汇独立的独立语音识别器,识别语言为阿马齐格语言。为了找出最佳的参数组合,将最佳的参数组合用来设计一个语音识别系统,设计出能够区分吸烟者和非吸烟者的声音的语音识别系统,为此我们进行了两个实验。在第一个实验中,系统只使用不吸烟者的声音进行训练和测试,而在第二个实验中,系统使用不吸烟者和吸烟者的声音进行训练和测试。表5给出了每个实验使用的训练方式和测试数据的更多细节。在这两个实验中,我们使用了不同的训练方式和测试参数来识别最佳组合,从而设计出一个有效的ASR系统,用来区分吸烟者和非吸烟者的声音。我们已经使用从4到32的不同的高斯值以及每个HMM的3和5个状态来训练和测试系统,对于所有的10位数字。表6显示了第一个实验的结果,该系统使用3和5 HMM的非吸烟者声音和4到32的高斯混合进行训练和测试。在3个HMM的情况下,4、8、16和32个GMMs的识别率分别为87.98、89.09、90.
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[239946],资料为PDF文档或Word文档,PDF文档可免费转换为Word

