
英语原文共 10 页,剩余内容已隐藏,支付完成后下载完整资料
语义分割的双超分辨率学习
Li Wang1, lowast;, Dong Li1, Yousong Zhu2, Lu Tian1, Yi Shan1
1 Xilinx Inc., Beijing, China.
2 Institute of Automation, Chinese Academy of Sciences, Beijing, China.
{liwa, dongl, lutian, yishan}@xilinx.com, yousong.zhu@nlpr.ia.ac.cn
摘要
目前最先进的语义分割方法往往应用高分辨率的输入来获得高性能,这带来了较大的计算预算,限制了它们在资源受限设备上的应用。本文提出了一种简单灵活的双流框架——双超分辨率学习(DSRL),在不引入额外计算成本的情况下,有效地提高了分割精度。具体而言,该方法由超分辨率语义分割(SSSR)、单图像超分辨率(SISR)和特征相似性(FA)模块三部分组成,可以在低分辨率输入的情况下保持高分辨率表示,同时降低模型计算复杂度。而且,它可以很容易地推广到其他任务,例如人类姿势估计。这种简单而有效的方法产生了很强的呈现,并通过语义分割和人类姿势估计的良好性能得到了证明。具体来说,对于CitySpaces上的语义分割,我们可以在相似的FLOP下实现ge;2%的mIoU,并将性能保持在70%的FLOP。对于人体姿势估计,我们可以在相同的FLOP下获得ge;2%的mAP,并以减少30%的FLOP维持mAP。代码和模型见https://github.com/wanglixilinx/DSRL.
1.引言
语义分割是场景理解的基本任务,旨在为图像中的所有像素分配密集的标签。它在自主驾驶、机器人传感等领域具有广阔的应用前景。对于大多数这样的应用来说,同时保持高效的推理速度和令人印象深刻的性能是一个挑战,特别是在资源有限的移动设备上。
由于深度学习的发展,语义分割也取得了显著的改进,
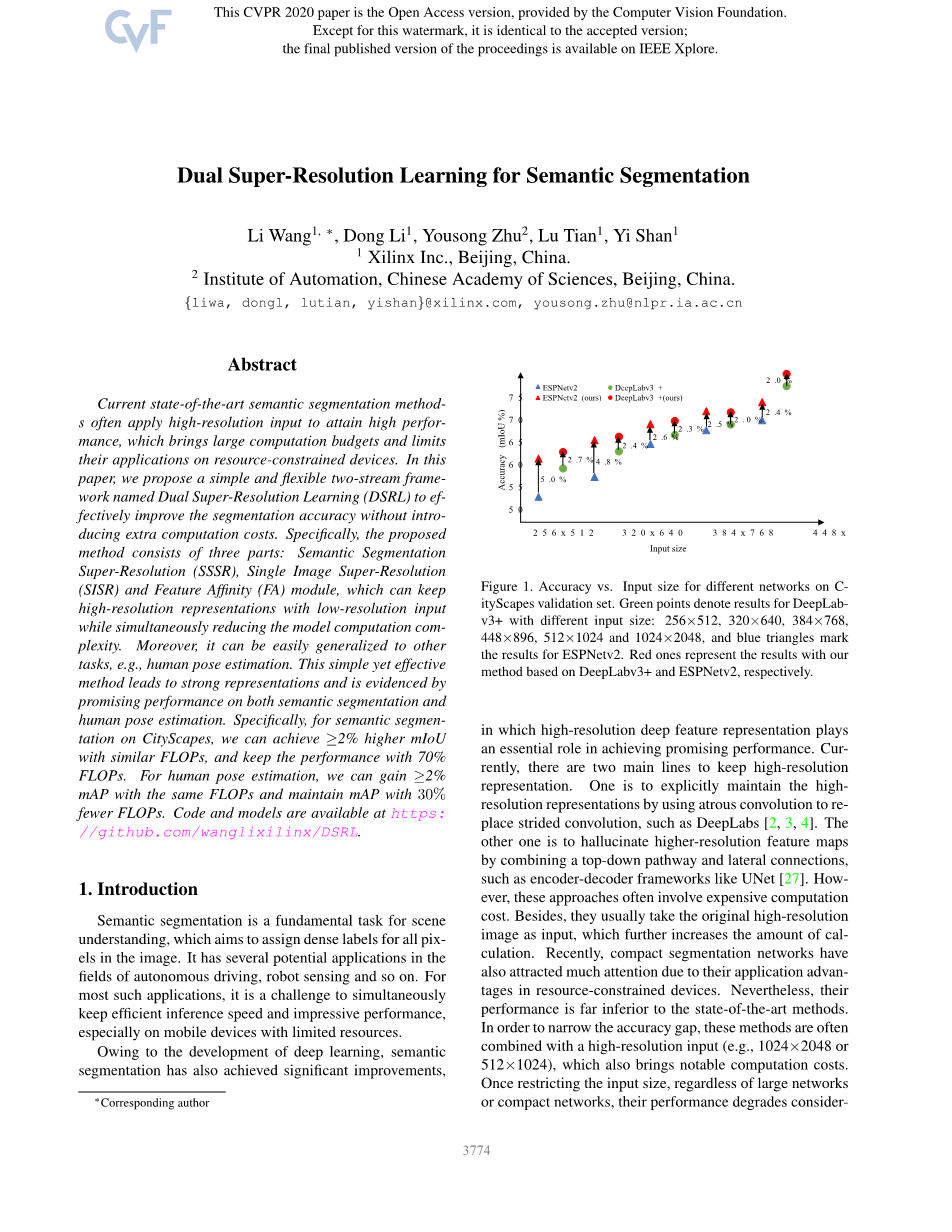
图1. CitySpaces验证集中不同网络的精度与输入大小。绿点表示输入尺寸不同的DeepLab-v3 的结果:256 times; 512、320 times; 640、384 times; 768、448 times; 896、512 times; 1024和1024 times; 2048,蓝色三角形表示ESPNetv2的结果。红色表示分别基于DeepLabv3 和ESPNetv2的copy;oCurp方法的结果。o
其中高分辨率的深度特征表示在实现有希望的性能中起着至关重要的作用。目前,有两条主线来保持高分辨率的表示。一种是通过使用atrous卷积来代替条纹卷积来明确维护高分辨率的表示,例如DeepLabs[2,3,4]。另一种是通过结合自上而下的路径和横向连接(例如UNet[27]等编码器-解码器框架)来幻觉更高分辨率的特征映射。然而,这些方法通常涉及昂贵的计算成本。此外,他们通常将原始的高分辨率图像作为输入,这进一步增加了计算量。最近,紧凑分割网络由于在资源约束设备中的应用优势也引起了广泛的关注。然而,它们的性能远劣于最先进的方法。为了缩小精度差距,这些方法往往与高分辨率输入(如1024 times; 2048或512 times; 1024)相结合,这也带来了值得注意的计算成本。一旦限制了输入的大小,不管是大网络还是紧凑网络,它们的性能都会极大下降。
图1显示了两个代表性分割网络的性能:具有各种输入分辨率的ESPNetv2[24]和DeepLab-v3 [4]。我们可以观察到,当输入分辨率从512 times; 1024降低到256 times; 512时,两个网络的精度都降低了10%以上。
因此,本文设计了一个清晰、简单的框架来缓解这一困境。具体来说,基于图像超分辨率(旨在用低分辨率输入重建高分辨率图像),我们提出了一种新的双超分辨率学习(DSR-L)范例来保持高分辨率的表示。这种学习方法是在双流框架中统一的,由语义分割超分辨率(SSSR)、单图像超分辨率(SISR)和特征亲和(FA)模块组成。更具体地说,我们将超分辨率的思想集成到现有的语义分割管道中,从而制定了语义分割超分辨率(SSSR)流。然后,通过具有特征亲和(FA)模块的SISR流的细粒度结构表示,进一步增强了SSSR流的高分辨率特征。而且,这两个流共享相同的特征提取器,SISR分支在训练过程中用重建监督进行优化,它会在推理阶段自由地从网络中移除,从而造成免费的开销。我们注意到,所提出的方法可以很容易地实现具有相似FLOP的较高mIoU,并保持具有较少FLOP的性能。如图1所示,我们提出的DSRL可以显著提高不同分辨率下的精度,尤其是对于低分辨率,从而可以显著降低计算成本,性能相当。与输入尺寸为320 times; 640的ESPNetv2相比,我们使用256 times; 512的低分辨率输入图像的方法可以获得2.4%的mIoU,同时减少36%的FLOPs。最后但同样重要的是,我们的框架可以很容易地扩展到其他需要高分辨率表示的任务,如人类姿势估计。广泛的实验证明了该方法在两个具有挑战性的数据集中的有效性和效率,例如,用于语义分割的CityScapes[5]和用于人体姿势估计的MS COCO[19]。
总之,我们的主要贡献包括:
(1) 我们提出了一种双超分辨率学习框架来保持高分辨率的表示,它可以在保持推理速度的同时提高性能;
(2) 我们验证了DSRL框架的通用性,它可以很容易地扩展到其他需要高分辨率表示的任务,如人类姿势估计。
(3) 我们证明了我们的方法在语义分割和人类姿势估计方面的有效性。有了类似的计算预算,我们可以提高ge; 2% 准确度,同时降低FLOP,性能相当。
2. 相关工作
语义分割。语义分割是一种密集的图像预测任务,在高级场景理解中起着关键作用。在卷积神经网络(CNN)快速发展的推动下,各种工作,FCN[21]、DeepLabs[2,3,4]、PSPNet[38]总是采用复杂的特征提取网络(例如,ResNet-s[12]和DenseNets[13])来学习密集预测的区分性特征表示。此外,现有的方法还开发了进一步提高性能的关键策略,包括atrous卷积[2,3,4]、金字塔汇集模块[38]、注意机制[14]、上下文编码[37]等。然而,这些方法总是涉及昂贵的计算,这限制了它们在资源受限设备上的应用。
同时,设计轻量级语义分割模型引起了社区的广泛关注。大多数工作集中在轻量级网络设计,通过加速卷积操作与因子分解技术。ESPNets[23,24]利用分裂合并或约简展开原理来加速卷积计算。其他一些采用有效的分类网络(例如MobileNet[28]和ShuffleNet[22])或一些压缩技术(例如修剪[9]和矢量量化[34])来加速分割。此外,[20]利用知识蒸馏,利用大型网络帮助训练紧凑型网络。然而,它们的性能远远不如最先进的模型。
与以往的方法不同,我们利用单幅图像超分辨率的高分辨率特征来指导空间维数的相关学习,从而有益于语义分割的任务。我们的方法可以显著提高性能,同时保持相似的FLOP。
单图像超分辨率。SISR是指从低分辨率图像中恢复高分辨率图像的过程。基于深度学习的SISR方法已被广泛提出,并在各种基准上实现了最先进的性能。最近,监督图像超分辨率方法主要有四种。(1)预上采样SR[7,6]应用传统的上采样操作(如双线性或双三次)来获得高分辨率图像,然后使用深度学习卷积网络对其进行细化。该框架需要更高的计算成本,因为大多数操作都是在高维空间中进行的。(2)上采样后SR[29,16,32]用集成在模型末端的端到端可学习的上采样层代替预定义的上采样操作,可以大大降低计算复杂度。(3)在后采样SR的基础上引入了渐进上采样SR[16,15,33],旨在通过逐步重建高分辨率图像来降低学习难度,并能应对多尺度SISR的需求。(4)迭代升降SR[13,10,31]
利用迭代上采样和下采样层生成中间图像,然后结合它们重建最终的高分辨率图像。考虑到高质量的结果和较低的计算成本,我们在本工作中遵循了我们的SISR分支的后采样SR方法的精神。
图2.提出的DSRL框架概述,包括三部分:语义分割超分辨率(SSSR)分支、单图像超分辨率(SISR)分支和特征亲和(FA)模块。编码器在SSSR分支和SISR分支之间共享。该体系结构将使用三个术语进行优化:SISR分支的MSE损失、FA损失和任务特定损失,例如语义分割的交叉熵损失。
多任务学习。多任务学习通常与CNN联合用于相关任务的建模,例如姿态估计和动作识别[8]、对象检测和实例分割[11]。这些方法通常在训练和测试阶段对多项任务一视同仁。然而,与跨任务模块设计的方法不同,我们将分割作为主要任务,将SISR作为辅助任务,在推理阶段去除图像超分辨率分支,不引入额外的计算成本。
3. 拟定方法
在本节中,我们首先回顾了最流行的用于语义分割的编码器-解码器体系结构。然后详细介绍了所提出的DSRL框架,最后简要介绍了优化函数。
3.1. 编码器-解码器框架综述
我们首先简要回顾了传统的语义分割编码器解码器体系结构。我们知道,编码器采用深度卷积神经网络来提取层次特征,缩放步长为2。这里,我们将输出步长(OS)表示为输入图像空间分辨率与编码器输出分辨率的比值。为了确保高性能,
OS通常等于16(或8),通过相应地用萎缩卷积替换最后一个(或两个)条纹卷积块。基于向下采样的特征映射,解码器直接利用具有OS比例因子的双线性向上采样层(例如,PSPNet[38])或简单设计的子网络(例如,DeepLabv3 [4]中的两个连续向上采样层)来细化分割结果。然而,现有的方法大多只能将特征映射上样到与输入图像相同的大小进行预测,这可能比原始图像小,例如在CityScapes中对1024 times; 2048到512 times; 1024的原始图像进行子采样作为网络输入,因此需要对地面实况进行向下采样以进行监督。一方面,这可能导致有效标签信息丢失。另一方面,仅依靠解码器很难恢复原始细节,制约了性能提高。
3.2. 双超分辨率学习
为了缓解上述困境,我们提出了一个简单有效的框架,命名为双超分辨率学习(DSRL),以有效地提高性能,而不需要计算和内存过载,特别是在低分辨率输入的情况下。如图2所示,我们的体系结构由三部分组成:(A)语义分割超分辨率(SSSR);(b)单图像超分辨率(SISR)和(c)特征亲和力(FA)模块。
语义分割超分辨率。对于语义分割,我们简单地附加了一个额外的上采样模块来产生最终的预测掩模,整个过程被命名为语义分割超分辨率(SSSR),例如,如图4(a)所示,输入512times;1024,我们将生成1024的输出times;2048,即2times; 比输入图像。与最近的系统相比,预测times;用于培训和测试的1024掩码(然后重新缩放至1024)times;2048在后处理阶段),我们的方法可以充分利用真相,避免预处理引起的有效标签信息丢失。我们额外的语
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[262611],资料为PDF文档或Word文档,PDF文档可免费转换为Word
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

