
英语原文共 8 页,剩余内容已隐藏,支付完成后下载完整资料
2018年IEEE第20届高性能计算与通信国际会议;IEEE第16届智能城市国际会议;IEEE第4届国际数据科学与系统会议
基于用户中心访问行为的在线学习框架
|
黄国浩 武汉大学电子信息学院 中国湖北武汉,maxwellhuang@whu.edu.cn |
郝江 武汉大学电子信息学院 中国湖北武汉jh@whu.edu.cn |
谢静 武汉大学电子信息学院 中国湖北武汉 Jing_x@whu.edu.cn |
|
曾元元 武汉大学电子信息学院中国湖北武汉zengyy@whu.edu.cn |
易舒文 武汉大学电子信息学院中国湖北武汉yishuwen@whu.edu.cn |
摘要:-随着5G技术的发展,移动边缘计算(MEC)已经成为在无线网络边缘部署服务器有效降低回程带宽消耗的新模式。与有线内容缓存不同的是,由于用户的时空移动性和无线边缘上不同的内容寿命,内容流行度分布呈现出多样性。有效地学习多样化内容的流行性成为自适应缓存的主要挑战。在通用MEC体系结构下,提出了一种基于用户中心访问行为(OLCB)的在线学习框架。OLCB通过以用户为中心的访问行为重构组首选项上下文,并及时了解上下文指定的内容流行度。当上下文到达时,对上下文空间进行自适应划分,以有效地估计不同情况下的内容流行程度。我们对现有的中国移动用户数据记录(UDR)数据集的实验表明,该方法明显优于现有的解决方案。
关键词:移动边缘计算;群体偏好;以用户为中心的访问行为;在线学习
- 介绍
现在的无线网络数据流量急剧增加。根据思科的报告,全球移动流量在2016年增长了63%,达到每月7.2eb[1]。到2021年,Wi-Fi和移动设备将占IP流量的63%[1]。为了减少回程带宽消耗,提出了移动边缘计算(MEC)的概念。[2]由欧洲电信标准协会(ETSI)于2004年提出。MEC服务器部署在网络边缘(如LTE中的Macro-BSS和Micro-BSS),在本地传输内容,有效降低回程带宽。在新的5G架构上,许多缓存策略(如cloud ran[3]、fog ran[4]和以内容为中心的网络(ccn)[5]也假设内容可以缓存在无线边缘上。
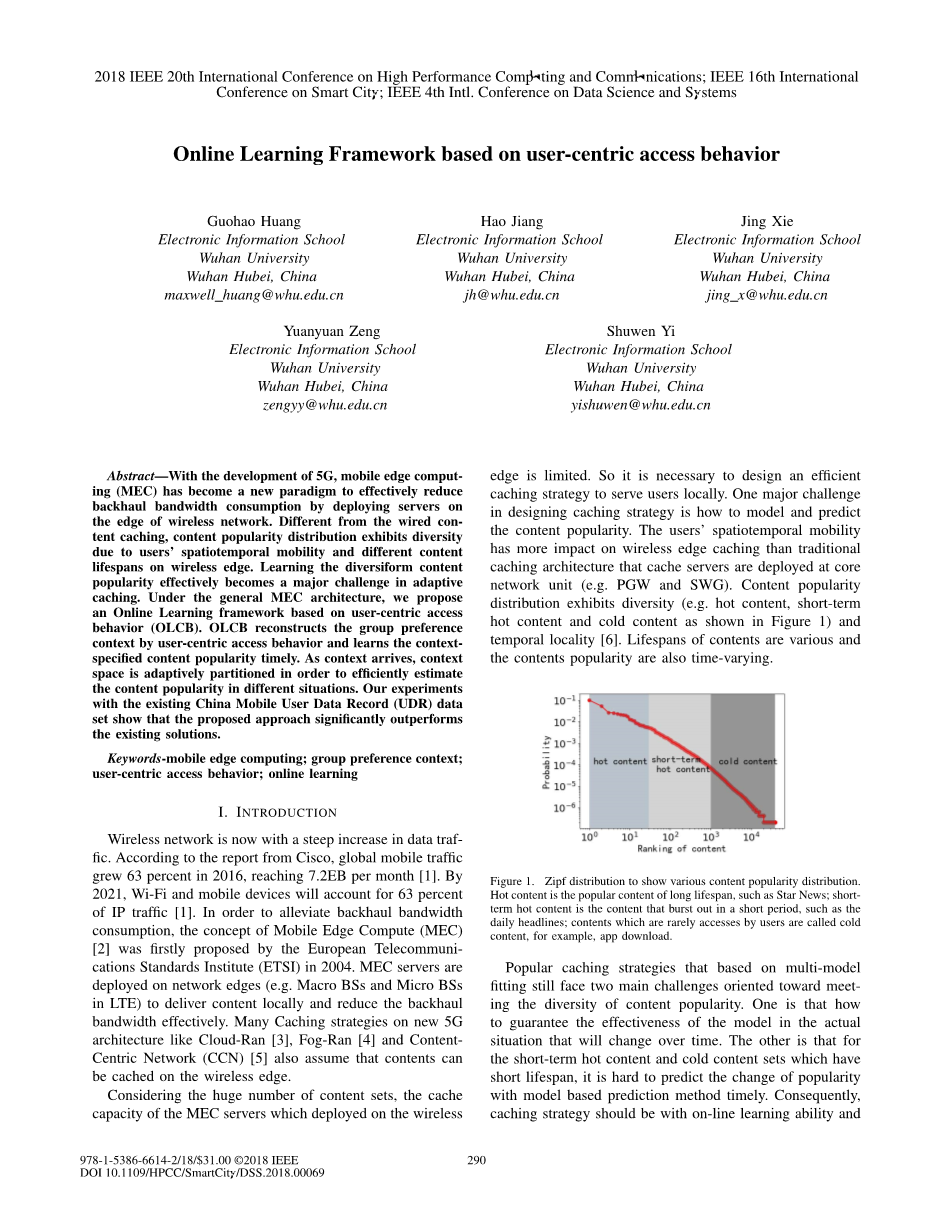
考虑到内容集数量巨大,部署在无线边缘的MEC服务器的缓存容量有限。因此,有必要设计一种有效的缓存策略,为本地用户提供服务。设计缓存策略的一个主要挑战是如何建模和预测内容的流行程度。用户的时空移动性对无线边缘缓存的影响比传统的缓存体系结构更大,缓存服务器部署在核心网络单元(如PGW和SWG)。内容人气分布呈现多样性(如图1所示的热含量、短期热含量和冷含量)和时间位置[6]。内容的寿命各不相同,内容的流行程度也随时间变化。
图1 Zipf发布,展示各种内容的流行分布。热门内容是长寿命的热门内容,如明星新闻;短期热门内容是短时间内突然出现的内容,如每日头条新闻;用户很少访问的内容称为冷内容,如应用下载。
基于多模型拟合的流行缓存策略仍然面临着面向满足内容流行多样性的两大挑战。一方面是如何保证模型在随时间变化的实际情况下的有效性。另一方面,对于寿命较短的短期热含量和冷含量集,用基于模型的预测方法难以及时预测其流行度的变化。因此,缓存策略应该具有在线学习能力,并且可以根据上下文的变化进行自适应调整,以确保性能,如图2所示。例如,我们可以使用用户偏好和在线记忆效应等机制来有效地探索不同特征的内容集。
Exploration observe Exploitation
discard
图2.利用探索法快速学习流行度变化的图解。
从另一个角度来看,正是用户的访问行为导致了内容流行度预测的复杂性。请求因不同的上下文而不同,如用户组组成、用户偏好和其他因素,因此在做出缓存决策时需要考虑上下文的影响。传统的时空特征是多余的,难以评估其有效性[7],因此使用用户访问行为重建上下文是一个合理的想法[8][9]。
本文提出了一种基于用户为中心的访问行为的在线学习框架OLCB,并通过探索开发过程实时了解上下文指定内容的流行程度。在OLCB框架中,我们首先利用用户访问行为的中心效应构造用户组上下文。然后提出了一种上下文缩放算法,该算法对上下文空间进行自适应划分,通过改进的搜索索引在线学习上下文内容对的平均奖励。本文的贡献如下:提出了一种基于用户中心访问行为的组偏好上下文构造方法。我们的方法利用用户访问行为的中心效应来重建传统的时空特征。提出了一种中心行为驱动的联合分析算法,挖掘了中心特征与内容特征的关系。我们的方法不那么复杂,可以广泛应用于其他包含时空信息和中心效应的数据集。·
我们提供了一个基于以用户为中心的访问行为的在线学习框架OLCB。我们的框架结合了内容流行的多样性,利用基于上置信度的探索,并考虑到用户偏好对其上下文的依赖性。
我们评估了缓存策略在真实中国移动UDR数据集上的有效性。结果表明,OLCB框架能够实现对现有方法的缓存效率的显著提高。
论文的其余部分组织如下。第二节审查相关工作。第三节描述了系统架构和问题的形成。第四节描述了基于中央访问行为的在线学习框架的详细信息。第五节用实际数据集报告我们的实验结果,并对结果进行分析。第六节结束论文。
- 相关工作
为了满足内容流行的多样性,人们提出了许多研究。简单的策略,如LRU、FIFO、LFU及其变体,由于其简单性,在一些复杂的系统中被使用,但它们也容易遭受较大的性能偏差。另一种缓存策略[10][11]基于经典时间序列预测方法(例如ARIMA)的预测方法未能考虑用户偏好对不同上下文的影响。
Wang等人[12]总结了缓存设计的现有模型和方法。例如,具有一定兴趣的社会群体运动可以用于自适应缓存。在[13]中,个体用户的时空移动模式和内容偏好通过回波状态网络进行建模。相反,K Poularakis等人[14]使用离散马尔可夫链对运动模式进行建模。但[13][14]中提出的方法由于计算复杂度高,不能应用于大用户集的场景,也不能考虑内容流行的多样性。
不同于使用复杂和特殊的模型来预测内容流行度,学习方法在[15][16][17][18]中被采用来预测未知的内容流行度。在[15]中,使用结合切换成本(CUCBC)的上置信限算法来确定内容缓存。但是,如果没有适当的约束,当勘探空间较大时,CUCBC很容易导致过度勘探。[16]中的方法通过提出一个zipf分布勘探约束来解决这个问题。此外,Suoheng Li等人[17]将缓存问题视为上下文多武装的强盗问题,提出了将过去n小时内请求内容的次数视为上下文的popcaching算法。在[18]中,使用用户的位置、年龄和性别作为上下文来预测内容的流行程度。目前将多臂Bandit算法应用于缓存设计的研究主要有以下三个方面:1)传统的多臂Bandit算法如ucb1[19]、ucb2[19]和epsilon greedy[19]与上下文无关,可能导致过度的探索更容易;2)由于隐私保护,大多数数据集中很难访问诸如年龄和性别等个人信息;3)内容缓存问题不同于广泛采用多臂强盗算法的推荐问题。是用户组决定缓存条目的内容首选项。
- [计]系统综述
- 系统框架层
我们认为,OLCB框架部署在5G Cloud-Ran架构的基本单元上,它由一个基带单元(BBU)和几个远程无线单元(RRU)组成,如图3所示。RRU通过前传链接连接到BBU,BBU通过回传链接从核心网络获取内容。具体来说,MEC服务器可以与RRU一起安装。当用户请求到达RRU时,如果内容存在于本地MEC服务器上,则直接将内容提供给用户,而不消耗反向带宽,否则通过反向链接从核心网络获取内容,然后发送给用户。
Control Center
Content Server
((dd))CContext Space Fiile ((e))Explorationamp;
Partition File Exploitation
)
4
Backhaul
UUser Group CConttext
3
Reward
plusmn; Estiimatte
F
MEC
Server
%%8
(b)Central feature Reward
Construction Reveal
File
)a
sup2;
Fronthaul
6
Cache Entry
(a)User Interface (b)Cache Managerment
558l
5584
5583
l
8
558sup2;
OLCB
图3 OLCB框架部署在云运行体系结构的基本单元中。RRU通过前传链接连接到BBU,BBU通过回传链接从核心网络获取内容。具体来说,MEC服务器可以与RRU一起安装。
OLCB框架由控制中心和缓存实体组成,控制中心部署在BBU中,缓存实体部署在MEC服务器上。控制中心由上下文空间模块和勘探开发模块组成。上下文空间模块负责所有上下文子空间的维护,勘探开发模块根据当前上下文进行勘探决策,缓存实体由3个模块、用户界面模块、中心特征重构模块和缓存管理模块组成。各模块功能描述如下:
bull;用户界面模块:获取当前连接用户ID等信息,识别用户请求,揭示缓存内容的真正回报。
bull;中心特征重构模块:通过当前连接的用户的时空信息重构中心特征,然后构造组偏好上下文。
bull;缓存管理模块:缓存一定数量的内容。如果用户请求的内容存在于本地MEC服务器中,则直接提供给用户;否则,从核心网络获取内容并传递给用户接口模块。
bull;上下文空间模块:根据阈值维护每个子空间、动态分区所需的所有上下文子空间和资源。
bull;探索利用模块:在当前上下文子空间中,我们使用改进的上置信界算法计算上下文和内容对的平均回报,并做出缓存更新决策。结果反馈到缓存管理模块。
用于缓存更新的OLCB缓存框架的流程如下:用户界面模块获取所有连接用户的时空特征1;中心特征重构模块将时空特征重构为中心特征,然后构造组首选项上下文2;上下文空间模块定位SP根据当前偏好定义的子空间con-text 3,其中勘探开发模块估计上下文内容对4的平均回报。然后做出缓存决策,反馈到缓存管理模块5;缓存管理模块通过后向链路从核心网络获取未缓存的内容;同时,经过一定时间后,用户界面将真实的奖励信息反馈给勘探开发模块times;6。
- 问题定式化
OLCB缓存框架的核心思想是利用用户中心行为重构用户组偏好上下文,并在探索性开发的在线学习模式基础上学习上下文特定内容的流行性。假设OLCB缓存框架在离散时隙T=1,2,hellip;在当前时隙t,构造了一个d维偏好上下文特征gtchi;。chi;是一个D维上下文空间,在不丧失一般性的情况下,我们将上下文空间chi;=[0,1]归一化。例如,如果特征值在0到50之间,则需要减少50倍。定义f为一组内容,在已知组上下文gt的前提下,对f F的观测报酬df(gt)服从一定的分布,其均值mu;f(gt)未知,其中mu;f(gt)=e(df(gt))。每一个观察到的奖励都可以看作是分布的随机样本。
缓存策略的目标是在有限的时间t内选择内容,以最大化累积命中率,如(1)所示。第一个约束表示内容缓存受缓存容量s的限制。第二个限制表示yf,t是一个二进制变量,其中1表示内容在当前时间t缓存在缓存实体中,如果不是,则为0。我们将时间t的缓存策略定义为pi;t=Ufisin;F yf,t f(gt)。
假设平均报酬mu;f(gt)是已知的任何群体背景gt和任何内容f,那么问题退化为经典背包问题。假设
所有内容的大小为1个单位,最优策略pi;_t
对于上下文中的缓存,gt是、、hellip;、
按平均估计报酬排名前几位的
。当j=1,2,hellip;,s,(2)满足:
我们将缓存内容的最优集合定义为所以缓存问题的最佳解决方案是(3): (3)
事实上,在实际情况下,不同上下文和不同内容的平均回报是未知的,因此缓存策略需要在探索(选择可能获得更高回报的内容)和开发(选择获得更高回报的内容)之间进行权衡。我们将缓存策略和最佳缓存策略之间的遗憾定义为(4):
对预测的随机性、上下文实现和所选内容进行期望。遗憾描述了由于未知的上下文动态而导致的损失,并给出了学习算法的总预期回报的收敛速度与(4)中的最优缓存策略的值。遗憾的是,请求总数没有减少,但我们希望增加的速度尽可能慢。任何遗憾在t中为次线性的算法,即r(t)=o(),使得gamma;lt;1,将根据平均报酬收敛到最优解,即。
学习的遗憾也为学习的速度提供了一个衡量标准。较小的遗憾将导致更快地收敛到最优平均回报。
- 关于以用户为中心的访问行为的在线学习框架
用户的时空移动导致基站与用户之间的连接时变。因此,不同基站的内容首选项随用户上下文的变化而变化。探索群体之间的关系和上下文和内容首选项可能会提高缓存性能。然而
全文共12292字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[2375]
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

