
英语原文共 12 页,支付完成后下载完整资料
理解应用于NLP的卷积神经网络
当我们听到卷积神经网络的时候,我们一般会联想到计算机视觉。CNNs(卷积神经网络)在图像分类方面取得了重大突破。从Facebook的图片自动标注到车辆的自动驾驶,CNNs在计算机视觉方面都处于核心地位。
如今,我们开始更多地将CNNs应用在自然语言处理(NLP)的问题上,并且已经取得了一些有趣的成果。 在这篇文章中,我将会尝试概述什么是CNNs(卷积神经网络),以及它是怎样被应用到NLP(自然语言处理)中的。CNNs背后的原理对于计算机视觉的用例来说更容易理解,所以我们先从这里开始,然后再慢慢的转向它在自然语言处理方面的应用。
什么是卷积?
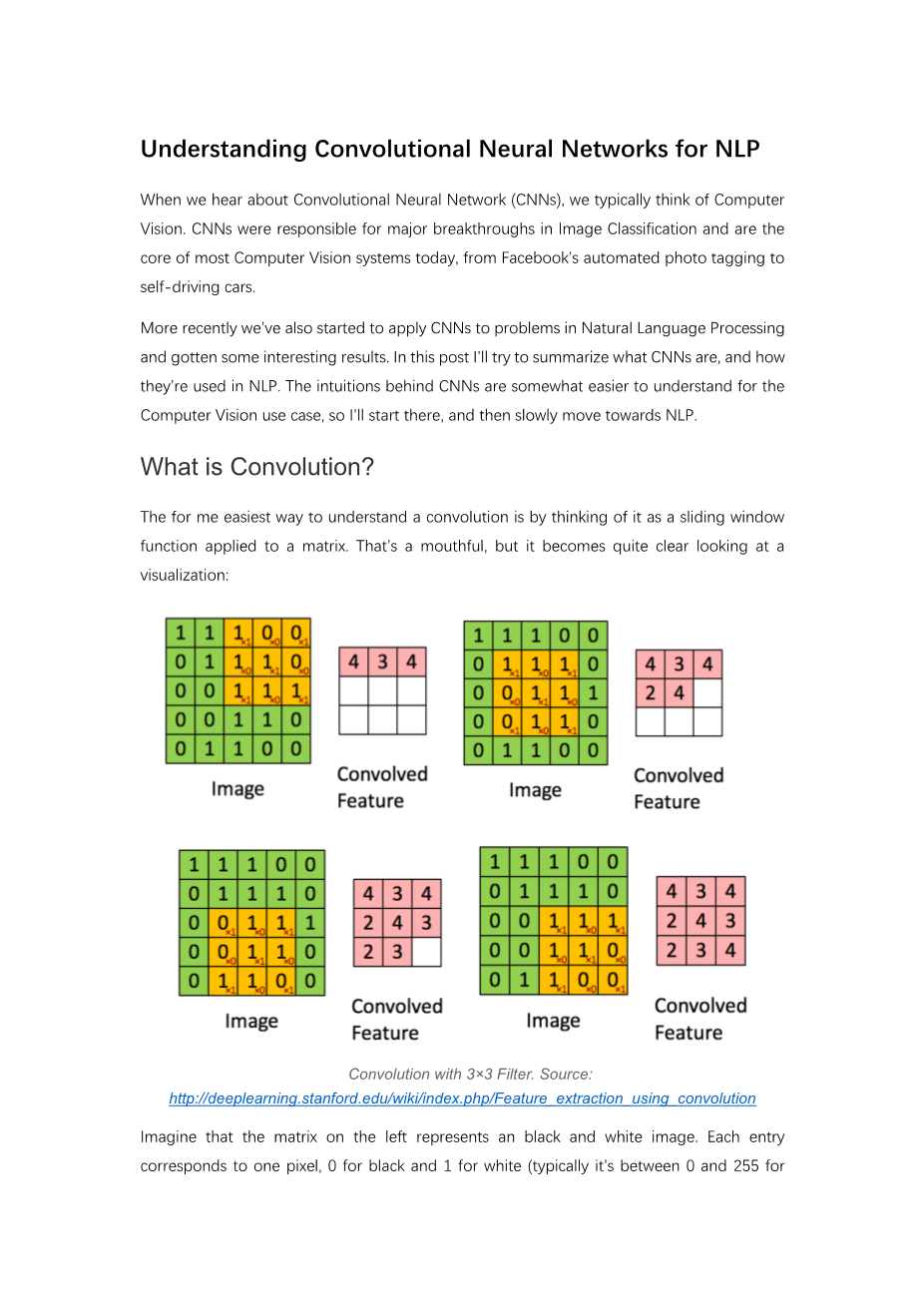
把卷积想成一个应用在数组上的滑动的窗口是一种让我们易于理解什么是卷积的方法。这是一个很能代表本质,但是从视觉上又很直观的例子:
基于3times;3 滤波器的卷积。资料来源: http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
想象一下,左边的矩阵代表黑白图像。每一个单元格代表一个像素,0代表黑色,1代表白色(对于灰度图来说,通常是0~255的数值)。滑动的窗口被称为核心、滤波器或者特征探测器。在这里我们使用3times;3的滤波器。将其元素值与原始矩阵相乘,然后将它们相加。为了获得完整的卷积,我们通过在整个矩阵上滑动滤波器来为每个元素执行此操作。你可能想知道您实际上可以做些什么。以下是一些直观的例子。
平均化像素的相邻值会使图像变得模糊不清:
利用相邻像素之间的差异来检测边缘:
(为了直观地理解这个例子,请思考在图像平滑的部分上上发生了什么。其中像素颜色等于其相邻的颜色:额外的抵消,导致结果值为0或黑色。如果是存在形状的边缘,例如,从白色到黑色的过渡,你会得到很大的差异,并产生白色值)
在GIMP手册有一些其他的例子。为了更多地了解卷积如何工作,我还建议查看Chris Olah关于该主题的帖子。
什么是卷积神经网络?
现在,你知道了什么是卷积。但是什么是卷积神经网络呢?卷积神经网络基本上是数层卷积网络,其中非线性激活函数如 “ReLU”(线性整流函数(Rectified Linear Unit, ReLU))或“tanh”(为双曲正切)应用于结果。在传统的前馈神经网络中,我们连接每一个输入神经元和下一层输出神经元。这也被称作完全连接层,或者仿射层。在卷积神经网络中,我们没必要这么做。相反,我们在每一个输入层上使用卷积计算输出。这导致局部连接,输入的每一个区域都被连接到一个输出神经元上面。每一层使用不同的滤波器,通常有成百上千像上面说的局部连接,并将其结果结合起来。这也被称作池化(采样)层,在后面我会具体介绍。在训练阶段,CNN会根据你想要执行的任务自动学习滤波器的值。例如,在图像分类中,CNN可以学习从第一层中的原始像素检测边缘,然后使用边缘检测第二层中的简单形状,然后使用这些形状来阻止更高级别的特征,例如面部形状在更高层。最后一层是使用这些高级功能的分类器。
这种计算方式有两个方面值得关注:位置不变性和组合性。假设你想要根据图像中是否有大象对图像进行分类。因为你在整个图像上滑动你的滤波器,你并不真的在乎大象出现在哪里。事实上,池化还可以为你提供平移、选择和缩放的不变性,这点在后面会有更多的介绍。第二个关键的方面是(局部)组合性。每一个滤波器会综合一小块局部区域的低级特征形成高级特征。这也是CNNs对计算机视觉作用巨大的原因。我们可以很直观地理解,线条由像素点构成,基本形状又由线条构成,更复杂的物体又源自基本的形状。
那么,如何将它们用于NLP呢?
NLP任务的输入不在是像素点了,而是由矩阵代表的句子或者文档。矩阵的每一行代表一个分词元素,通常是一个单词,也可以是一个字符。也就是说每一行是一个代表单词的向量。一般来说,这些向量都是词嵌入(一种低维度的表示)的形式,像word2vec或者GloVe。但是也可以用one-hot向量的形式,也即根据词在词表中的索引。若是用100维的词向量表示一句10个单词的句子,我们将得到一个10x100维的矩阵作为输入。这个矩阵相当于是一幅“图像”。
在计算机视觉的例子里,我们的滤波器每次只对图像的一小块区域运算,但在处理自然语言时滤波器通常覆盖上下几行(几个词)。因此,滤波器的宽度也就和输入矩阵的宽度相等了。尽管高度,或者区域大小可以随意调整,但一般滑动窗口的覆盖范围是2~5行。综上所述,处理自然语言的卷积神经网络结构是这样的(花几分钟时间理解这张图片,以及维度是如何变化的。你可以先暂时忽略池化操作,我们在稍后会解释它):
用于句子分类器的卷积神经网络(CNN)结构示意图。这里我们对滤波器设置了三种尺寸:2、3和4行,每种尺寸各有两种滤波器。每个滤波器对句子矩阵做卷积运算,得到(不同程度的)特征字典。然后对每个特征字典做最大值池化,也就是只记录每个特征字典的最大值。这样,就由六个字典生成了一串单变量特征向量(univariate feature vector),然后这六个特征拼接形成一个特征向量,传给网络的倒数第二层。最后的softmax层以这个特征向量作为输入,用其来对句子做分类;我们假设这里是二分类问题,因此得到两个可能的输出状态。
计算机视觉完美的直观感受这里还存在吗?位置不变性和局部组合性对图像来说很直观,但对NLP却并非如此。你也许会很在意一个词在句子中出现的位置。相邻的像素点很有可能是相关联的(都是物体的同一部分),但单词并不总是如此。在很多种语言里,短语之间会被许多其它词所隔离。同样,组合性也不见得明显。单词显然是以某些方式组合的,比如形容词修饰名词,但若是想理解更高级特征真正要表达的含义是什么,并不像计算机视觉那么明显了。
由此看来,卷积神经网络似乎并不适合用来处理NLP任务。递归神经网络(Recurrent Neural Network)更直观一些。它们模仿我们人类处理语言的方式(至少是我们自己所认为的方式):从左到右的顺序阅读。庆幸的是,这并不意味着CNNs没有效果。所有的模型都是错的,只是一些能被利用。实际上CNNs对NLP问题的效果非常理想。正如词袋模型(Bag of Words model),它明显是基于错误假设的过于简化模型,但这不影响它多年来一直被作为NLP的标准方法,并且取得了不错的效果。
CNNs的主要特点在于速度快。非常的快。卷积运算是计算机图像的核心部分,在GPU级别的硬件层实现。相比于n-grams,CNNs表征方式的效率也更胜一筹。由于词典庞大,任何超过3-grams的计算开销就会非常的大。即使Google也最多不超过5-grams。卷积滤波器能自动学习好的表示方式,不需要用整个词表来表征。那么用尺寸大于5行的滤波器完全合情合理了。我个人认为许多在第一层学到的滤波器扑捉到的特征与n-grams非常相似(但不局限),但是以更紧凑的方式表征。
CNN的超参数
在解释如何将CNNs用于NLP任务之前,先来看一下构建CNN网络时需要面临的几个选择。希望这能帮助你更好地理解相关文献。
窄卷积 vs 宽卷积
在上文中解释卷积运算的时候,我忽略了如何使用滤波器的一个小细节。在矩阵的中部使用3x3的滤波器没有问题,在矩阵的边缘该怎么办呢?左上角的元素没有顶部和左侧相邻的元素,该如何滤波呢?解决的办法是采用补零法(zero-padding)。所有落在矩阵范围之外的元素值都默认为0。这样就可以对输入矩阵的每一个元素做滤波了,输出一个同样大小或是更大的矩阵。补零法又被称为是宽卷积,不使用补零的方法则被称为窄卷积。1D的例子如图所示:
窄卷积 vs 宽卷积。滤波器长度为5,输入长度为7。来源:A Convolutional Neural Network for Modelling Sentences (2014)
当滤波器长度相对输入向量的长度较大时,你会发现宽卷积很有用,或者说很有必要。在上图中,窄卷积输出的长度是 (7-5) 1=3,宽卷积输出的长度是(7 2*4-5) 1=11。一般形式为
步长
卷积运算的另一个超参数是步长,即每一次滤波器平移的距离。上面所有例子中的步长都是1,相邻两个滤波器有重叠。步长越大,则用到的滤波器越少,输出的值也越少。下图来自斯坦福的cs231课程网页,分别是步长为1和2的情况:
卷积步长。左侧:步长为1,右侧:步长为2。来源:
http://cs231n.github.io/convolutional-networks/
在文献中我们常常见到的步长是1,但选择更大的步长会让模型更接近于递归神经网络,其结构就像是一棵树。
池化层
卷积神经网络的一个重要概念就是池化层,一般是在卷积层之后。池化层对输入做降采样。常用的池化做法是对每个滤波器的输出求最大值。我们并不需要对整个矩阵都做池化,可以只对某个窗口区间做池化。例如,下图所示的是2x2窗口的最大值池化(在NLP里,我们通常对整个输出做池化,每个滤波器只有一个输出值):
CNN的最大池化。
为什么要池化呢?有许多原因。
池化的特点之一就是它输出一个固定大小的矩阵,这对分类问题很有必要。例如,如果你用了1000个滤波器,并对每个输出使用最大池化,那么无论滤波器的尺寸是多大,也无论输入数据的维度如何变化,你都将得到一个1000维的输出。这让你可以应用不同长度的句子和不同大小的滤波器,但总是得到一个相同维度的输出结果,传入下一层的分类器。
池化还能降低输出结果的维度,(理想情况下)却能保留显著的特征。你可以认为每个滤波器都是检测一种特定的特征,例如,检测句子是否包含诸如“not amazing”等否定意思。如果这个短语在句子中的某个位置出现,那么对应位置的滤波器的输出值将会非常大,而在其它位置的输出值非常小。通过采用取最大值的方式,能将某个特征是否出现在句子中的信息保留下来,但是无法确定它究竟在句子的哪个位置出现。这个信息出现的位置真的很重要吗?确实是的,它有点类似于一组n-grams模型的行为。尽管丢失了关于位置的全局信息(在句子中的大致位置),但是滤波器捕捉到的局部信息却被保留下来了,比如“not amazing”和“amazing not”的意思就大相径庭。
在图像识别领域,池化还能提供平移和旋转不变性。若对某个区域做了池化,即使图像平移/旋转几个像素,得到的输出值也基本一样,因为每次最大值运算得到的结果总是一样的。
通道
我们需要了解的最后一个概念是通道。通道即是输入数据的不同“视角”。比如说,做图像识别时一般会用到RGB通道(红绿蓝)。你可以对每个通道做卷积运算,赋予相同或不同的权值。你也同样可以把NLP想象成有许多个通道:把不同类的词向量表征(例如word2vec和GloVe)看做是独立的通道,或是把不同语言版本的同一句话看作是一个通道。
卷积神经网络在自然语言处理的应用
我们接下来看看卷积神经网络模型在自然语言处理领域的实际应用。我试图去概括一些研究成果。希望至少能够涵盖大部分主流的成果,难免也会遗漏其它一些有意思的应用(请在评论区提醒我)。
最适合CNNs的莫过于分类任务,如语义分析、垃圾邮件检测和话题分类。卷积运算和池化会丢失局部区域某些单词的顺序信息,因此纯CNN的结构框架不太适用于PoS Tagging和Entity Extraction等顺序标签任务(也不是不可能,你可以尝试输入位置相关的特征)。
文献[1gt;在不同的分类数据集上评估CNN模型,主要是基于语义分析和话题分类任务。CNN模型在各个数据集上的表现非常出色,甚至有个别刷新了目前最好的结果。令人惊讶的是,这篇文章采用的网络结构非常简单,但效果相当棒。输入层是一个表示句子的矩阵,每一行是word2vec词向量。接着是由若干个滤波器组成的卷积层,然后是最大池化层,最后是softmax分类器。该论文也尝试了两种不同形式的通道,分别是静态和动态词向量,其中一个通道在训练时动态调整而另一个不变。文献[2]中提到了一个类似的结构,但更复杂一些。文献[6]在网络中又额外添加了一个层,用于语义聚类。
Kim, Y. (2014). 卷积神经网络用来语句分类
文献[4]从原始数据训练CNN模型,不需要预训练得到word2vec或GloVe等词向量表征。它直接对one-hot向量进行卷积运算。作者对输入数据采用了节省空间的类似词袋表征方式,以减少网络需要学习的参数个数。在文献[5]中作者用了CNN学习得到的非监督式“region embedding”来扩展模型,预测文字区域的上下文内容。这些论文中提到的方法对处理长文本(比如影评)非常有效,但对短文本(比如推特)的效果还不清楚。凭我的直觉,对短文本使用预训练的词向量应该能比长文本取得更好的效果。
搭建一个CNN模型结构需要选择许多个超参数,我在上文中已经提到了一些:输入表征(word2vec, GloVe, one-hot),卷积滤波器的数量和尺寸,池化策略(最大值、平均值),以及激活函数(ReLU, tanh)。文献[7]通过多次重复实验,比较了不同超参数对CNN模型结构在性能和稳定性方面的影响。如果你想自己实现一个CNN用于文本分类,可以借鉴该论文的结果。其主要的结论有最大池化效果总是好于平均池化;选择理想的滤波器尺寸很重要,但也根据任务而定需;正则化在NLP任务中的作用并不
资料编号:[3260]
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

