
英语原文共 18 页,剩余内容已隐藏,支付完成后下载完整资料
第五章
深度学习
现在该进行深度学习了。 不过,您不必紧张。 由于深度学习仍是神
经网络的扩展,因此您以前阅读的大多数内容都适用。 因此,您没有太多其他要学习的概念。
简而言之,深度学习是一种采用深度神经网络的机器学习技术。 如
您所知,深度神经网络是包含两个或多个隐藏层的多层神经网络。 尽管
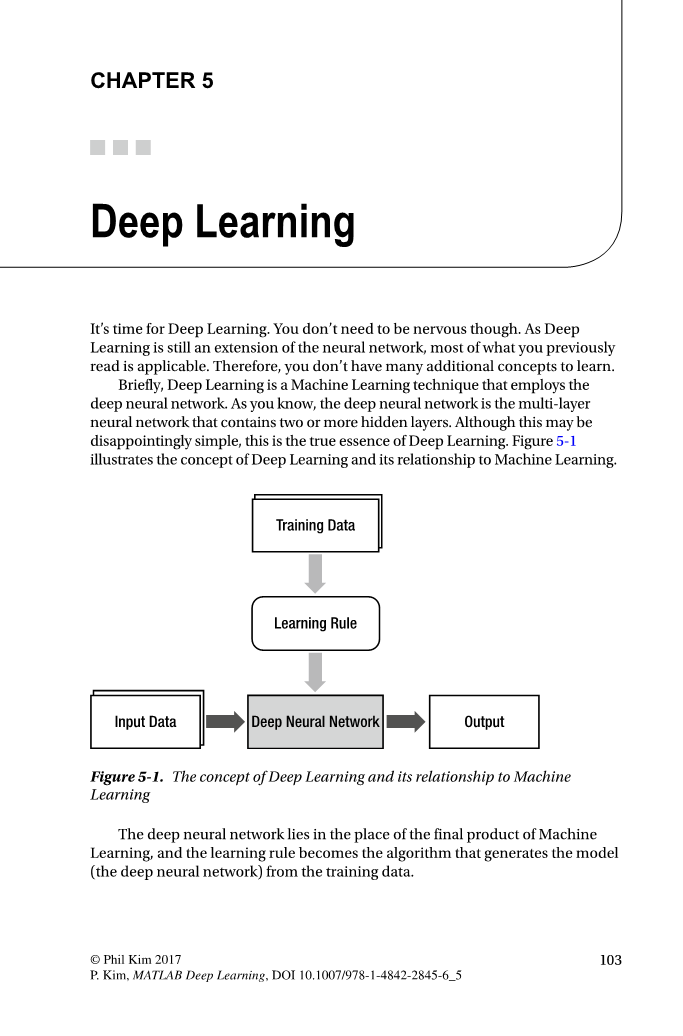
这可能令人失望地简单,但这是深度学习的真正本质。 图5-1展示了深度
学习的概念及其与机器学习的关系。
训练数据
学习规则
输入数据
深度神经网络
输出
图5-1。 深度学习的概念及其与机器学习的关系
copy;菲尔·金2017
103
P.Kim,MATLAB深度学习,DOI 10.1007 / 978-1-4842-2845-6_5
第五章 ■ 深度学习
现在,知道深度学习只是使用更深(更隐藏的层)神经网络的情况
下,您可能会问:“是什么让深度学习如此吸引人?有没有人想到过使神
经网络的层次更深?”为了回答这些问题,我们需要研究神经网络的历史。
单层神经网络,即第一代神经网络,在解决机器学习所面临的实际问
题时花了很短的时间。sup1;研究人员已经知道,多层神经网络将成为下一个
突破。但是,花了大约30年的时间才将另一层添加到单层神经网络。可
能不容易理解为什么只花一个额外的时间就花了这么长时间。这是因为
未找到用于多层神经网络的正确学习规则。由于训练是神经网络存储信
息的唯一方法,因此不可训练的神经网络毫无用处。
1986年引入反向传播算法后,多层神经网络的训练问题终于得到解
决。神经网络又重新上台了。 但是,很快又遇到了另一个问题。它在实际
问题上的表现没有达到预期。当然,人们进行了各种尝试来克服这些限
制,包括添加隐藏层和在隐藏层中添加节点。但是,它们都不起作用。他
们中许多人的表现甚至更差。由于神经网络具有非常简单的体系结构和概
念,因此没有什么可改进的事情。最后,神经网络被判处无法改善,并被遗忘。
直到2000年代中期深度学习被引入并打开一扇新门之时,它一直被遗
忘了约20年。 由于难以训练深层神经网络,因此深层隐藏层需要一段时
间才能产生足够的性能。无论如何,深度学习中的当前技术产生了令人眼
花levels乱的性能水平,其性能超过了其他机器学习技术和其他神经
网络,并在人工智能研究中占了上风。
1 如第2章所述,单层神经网络只能解决线性可分离的问题。
104
综上所述,多层神经网络解决单层神经网络问题需要30年的原因是
缺乏学习规则,最终通过反向传播算法得以解决。相比之下,直到基于
深度神经网络的深度学习的引入又过了20年,才是性能不佳的原因。具
有额外隐藏层的反向传播训练通常会导致较差的性能。深度学习为该问题提供了解决方案。
深度神经网络位于机器学习最终产品的位置,学习规则成为从训练数
据生成模型的算法(深度神经网络)。
第五章 ■ 深度学习
消失梯度
在这种情况下,可以将梯度视为与反向传播算法的增量类似的概
念。当输出误差更可能无法到达更远的节点时,在使用反向传播算法的训
练过程中会消失梯度。反向传播算法在将输出错误向后传播到隐藏层时训
练神经网络。
但是,由于错误几乎不会到达第一隐藏层,因此无法调整权重。因
此,没有正确训练接近输入层的隐藏层。如果无法对隐藏层进行训练,那
就没有必要添加它们了(见图5-2)。
105
bull;
bull;
bull;
消失梯度
过度拟合
计算负荷
尽管取得了杰出的成就,但深度学习实际上没有任何关键技术可提
供。深度学习的创新是许多小的技术改进的结果。本部分简要介绍了为什
么深度神经网络产生较差的性能以及深度学习如何克服此问题。
具有较深层的神经网络产生较差性能的原因是该网络没有经过适当训
练。反向传播算法在深度神经网络的训练过程中遇到以下三个主要困难:
深度神经网络的改进
第五章 ■ 深度学习
图5-2。 消失的梯度
消失梯度的代表性解决方案是使用整流线性单元(ReLU)作为激活函
数。已知比S型函数更好地传输错误。ReLU函数的定义如下:
图5-3描绘了ReLU功能。 它为负输入产生零,并为正输入传递输入。sup2;它的实现也非常容易。
2
它的名称与整流器类似,是一种电气元件,它在切断负电压时将交流电转换为直流电,因此得名。
106
第五章 ■ 深度学习
图5-3。ReLU功能
乙字函数将节点的输出限制为单位,而不管输入的大小如何。 相反,
ReLU功能没有施加这样的限制。 这样简单的变化就可以极大地改善深度神
经网络的学习性能,这是否有趣?
反向传播算法需要的另一个元素是ReLU函数的导数。根据ReLU函数的
定义,其导数为:
此外,交叉熵驱动的学习规则可以提高性能,如第3章所述。此外,
高级梯度下降是一种更好地获得最佳值的数值方法,也有利于深层神经的
训练。
过度拟合
深度神经网络特别容易过拟合的原因是该模型变得更加复杂,因为它
包含了更多的隐藏层,因此也增加了权重。如第1章所述,复杂的模型更
容易过拟合。这是一个两难境地—深化更高的层以提高性能会驱动神经
网络面对机器学习的挑战。
3
sebastianruder.com/optimizing-gradient-descent/
107
第五章 ■ 深度学习
最具代表性的解决方案是Dropout,它仅训练一些随机选择的节点,
而不训练整个网络。 它非常有效,但其实现不是很复杂。 图5-4解释了
辍学的概念。 某些节点以一定百分比随机选择,其输出设置为零以停用
节点。
图5-4。辍学是随机选择某些节点并将其输出设置为零以停用节点的地方
辍学可以有效地防止过度拟合,因为它会在训练过程中不断改变
节点和权重。对于隐藏层和输入层,足够的辍学百分比分别约为50%和25%。
108
第五章 ■ 深度学习
防止过度拟合的另一种流行方法是在成本函数中添加正则化项,以提
供权重的大小。这种方法之所以有效,是因为它尽可能地简化了神经网
络的架构,从而减少了过拟合的发生。第3章说明了这一方面。此外,由于减少了因特定数据而引起的潜在偏差,因此使用大量训练数据也非常
有帮助。
计算负荷
最后的挑战是完成培训所需的时间。权重的数量随着隐藏层的数量在
几何上增加,因此需要更多的训练数据。最终,这需要进行更多的计算。
神经网络执行的计算越多,训练所需的时间就越长。在神经网络的实际开
发中,这个问题是一个严重的问题。如果深度神经网络需要一个月的训练
时间,则一年只能修改20次。在这种情况下,几乎不可能进行有用的研
究。通过引入高性能硬件(例如GPU)和算法(例如批量归一化),已在
很大程度上减轻了这一麻烦。
本节介绍的微小改进是使“深度学习”成为机器学习英雄的驱动程
序。机器学习的三个主要研究领域通常被称为图像识别,语音识别和自然
语言处理。这些领域中的每一个都已通过特别合适的技术进行了单独研
究。但是,深度学习目前优于这三个领域的所有技术。
示例:ReLU和Dropout
本部分实现ReLU激活功能和辍学(深度学习的代表技术)。它重用
了第4章中的数字分类示例。训练数据是相同的五乘五的正方形图像。
图5-5。 五乘五的正方形图像中的训练数据
109
第五章 ■ 深度学习
考虑具有三个隐藏层的深度神经网络,如图5-6所示。每个隐藏层包
含20个节点。该网络具有用于矩阵输入的25个输入节点和用于五类的五
个输出节点。输出节点采用softmax激活功能。
图5-6。 具有三个隐藏层的深度神经网络
ReLU功能
本节通过示例介绍ReLUfunction。 函数DeepReLU使用反向传播算法训练
给定的深度神经网络。 它获取网络和训练数据的权重,并返回训练后的
权重。
[W1, W2, W3, W4] = DeepReLU(W1, W2, W3, W4, X, D)
其中W1,W2,W3和W4分别是input-hidden1,hidden1-hidden2,hidden2-
hidden3和hidden3-outputlayer的权重矩阵。X和D是训练数据的输入矩
阵和正确的输出矩阵。以下清单显示了DeepReLU.m文件,该文件实现了
DeepReLU函数。
function [W1, W2, W3, W4] = DeepReLU(W1, W2, W3, W4, X, D)
alpha = 0.01;
N = 5;
for k = 1:N
x
= reshape(X(:, :, k), 25, 1);
v1 = W1*x;
y1 = ReLU(v1);
110
Chapter 5 ■ Deep Learning
v2 = W2*y1;
y2 = ReLU(v2);
v3 = W3*y2;
y3 = ReLU(v3);
v
y
= W4*y3;
= Softmax(v);
d
e
= D(k, :);
= d - y;
delta = e;
e3
= W4*delta;
delta3 = (v3 gt; 0).*e3;
e2
= W3*delta3;
delta2 = (v2 gt; 0).*e2;
e1
= W2*delta2;
delta1 = (v1 gt; 0).*e1;
dW4 = alpha*delta*y3;
W4 = W4 dW4;
dW3 = alpha*delta3*y2;
W3 = W3 dW3;
dW2 = alpha*delta2*y1;
W2 = W2 dW2;
dW1 = alpha*delta1*x;
W1 = W1 dW1;
end
end
此代码导入训练数据,使用delta规则计算权重更新(dW1,dW2,dW3
和dW4),并调整神经网络的权重。到目前为止,该过程与以前的培训代
码相同。唯一不同的是,隐藏节点使用功能ReLU代替了S型。当然,使用不
同的激活函数也会导致其导数发生变化。现在,让我们看一下DeepReLU函数调用的ReLU函数。ReLU.mfile中实现了此处显示的ReLU函数列表。由
于这仅是一个定义,因此不再赘述。
111
第五章 ■ 深度学习
function y = ReLU(x)
y = max(0, x);
end
考虑反向传播算法部分,该部分使用反向传播算法调整权重。以下清
单显示了DeepReLU.mfile中增量计算的摘录。此过程从输出节点的增量开
始,计算隐藏节点的错误,并将其用于下一个错误。它通过delta3,
delta2和delta1重复相同的步骤。
...
e
= d - y;
delta = e;
e3
= W4*delta;
delta3 = (v3 gt; 0).*e3;
e2
= W3*d
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[239993],资料为PDF文档或Word文档,PDF文档可免费转换为Word

