
英语原文共 8 页,剩余内容已隐藏,支付完成后下载完整资料
基于MEMS加速度传感器的非特定用户的手势识别
摘要:本文介绍了三种不同的手势识别模型,它们能够基于MEMS 3轴加速度计的输入信号识别7种手势,即上,下,左,右,打钩,圆圈和交叉。运动中的手的三个相互垂直方向的加速度数据由三个加速度计分别检测并通过蓝牙无线协议传送到PC。本文开发了一种自动手势分割算法,用来确定序列中的个别手势。为压缩数据以及最大限度地减小不同的用户做同种手势时有差异的影响,提取了一种基于手势加速度的符号序列的基本特征。这种方法将数百种单一手势的数据值减少到8种。最后,该手势是由手势编码与所存储的模板进行匹配。基于72个实验的结果,每个实验包含一系列手势(共628手势),这些实验表明,本文中讨论的三种模型最高实现了95.6%的总体识别准确率,每种手势的正确识别率从91%至100%。综上,我们可以得到结论,本文所提出的基于符号序列和模板匹配的识别算法可以用于非特异性用户手手势识别,无需耗费用户在手势识别过程中训练的时间。
关键词 手势识别 交互控制器 MEMS加速度计
1 简介
在我们的日常生活中,人机交互的增加使得用户界面技术越来越重要。肢体语言直观的表达将大大缓解交互过程,使人类更自然控制计算机或机器。例如,在遥控机器人领域,机器人奴隶已经能够跟着主人远程的手部动作运动[1]。其他被提及的识别手势的应用领域包括在3D空间使用惯性传感器进行角色识别[2],[3],手势识别远程控制电视机[4],使用手作为三维鼠标[5],在虚拟现实里用手势作为控制机构[6]。此外,手势识别还被提出用于了解音乐控制器[7]的动作。在我们的工作中,一个基于微型MEMS加速度计的识别系统被构建了出来,该系统可以在3D空间识别7种手势。该系统还具有潜在的用途,例如可以作为视觉和音频设备的遥控器,或作为一种控制办公室及工厂的机器和智能系统的控制机制。
多种现有设备可以捕捉手势,诸如“Wiimote的”操纵杆,轨迹球和触摸板。他们中的大部分也可以被用来提供输入数据到手势识别器。但有时,用于捕获手势所采用的技术是相对昂贵的,诸如视觉系统或数据手套[8]。为了使得收集数据的准确性和设备的成本之间能够平衡,一个微惯性测量单元(mu;IMU)被用在这个项目中,以检测手部动作在三个维度的加速度。
现有的手势识别方法主要有两种,即基于视觉和加速度计或陀螺仪。基于视觉的方法由于受到诸如意外环境光噪声,速度较慢的动态响应,以及相对大的数据集合,较复杂的处理过程限制[9],我们的识别系统并没有采用基于视觉的方法,而是基于MEMS加速度传感器这样的惯性测量单元实现。因为如果陀螺仪被用于惯性测量将会带来的繁重的计算负担[10],所以我们目前的系统没有采用陀螺仪而是仅仅采用MEMS加速度计检测来实现。
现有手势识别方法包括模板匹配[11],字典查找[12],统计匹配[13],语言匹配[14],以及神经网络[15]。对于连续的数据,如测量的时间序列和用于语音识别的声学特征测量的连续的时间帧,HMM(隐马尔可夫模型)是最重要的模式之一[16]。它用于空间和时间变化模式的识别是有效的[17]。在本文中,我们提出了三个不同的手势识别模型,分别是:1)基于符号序列和霍普菲尔德理论的手势识别模型; 2)基于速度增量的手势识别模型; 3)基于符号序列和模板匹配的手势识别模型。在这三种模型中,为了找到一种简单而有效的解决基于MEMS加速度计的手势识别问题的方案,加速度不转换为速度,位移或者转化到频域,而是直接在时域上分割并且识别。通过提取一种基于加速度传感器符号序列的简单特征,识别系统实现了高准确率,高效率而不需要隐马尔可夫模型的应用。
2 手势动作分析
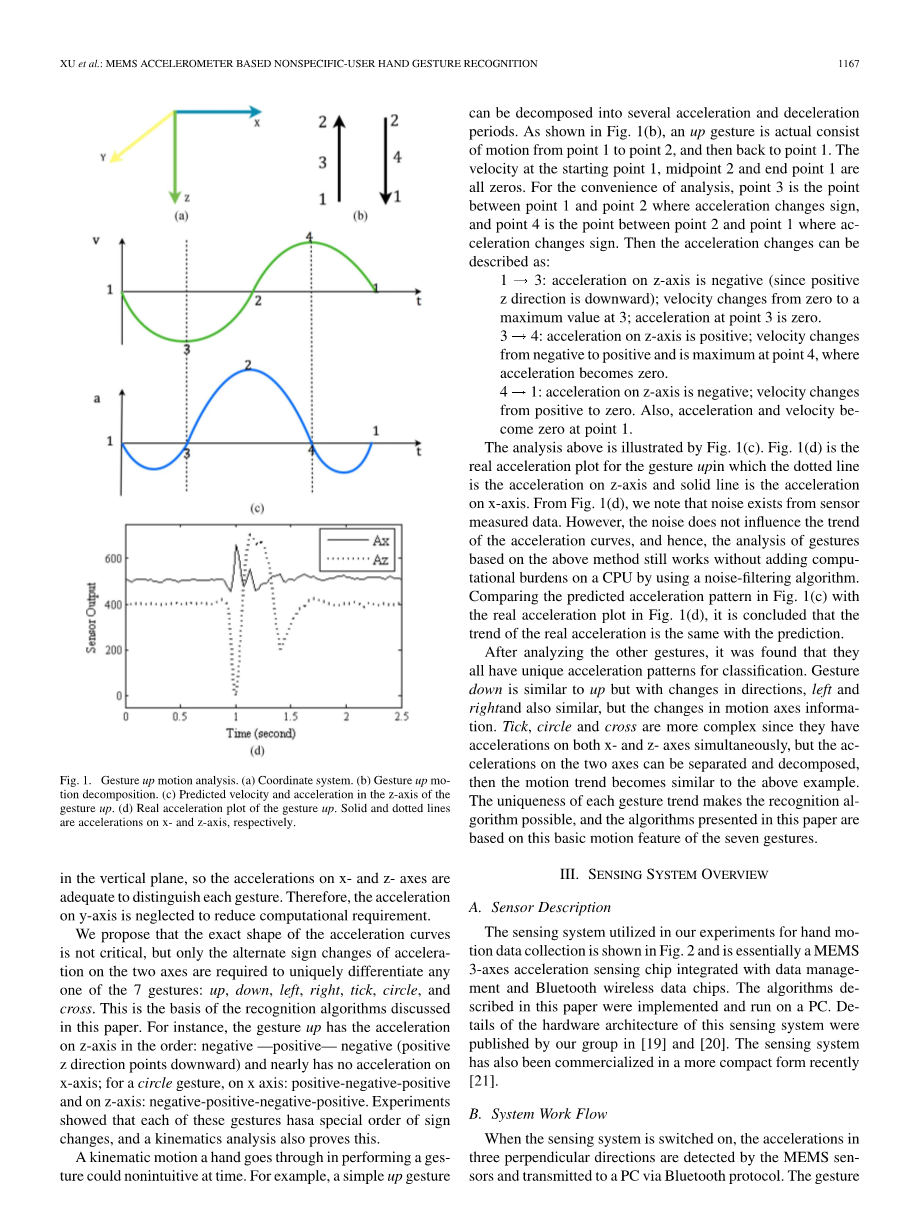
手势运动是在垂直平面内(如图1(a)中定义的x-z平面。)或运动的方向主要是在垂直平面内,所以对x轴和z-轴方向的加速度进行分析是足够区分每个手势的。因此,对于y轴的加速度可以忽略,这样可以减少计算量。
图1.上手势动作分析。(a)坐标系。(b)上手势动作分解。(c)预测上手势在Z轴上的速度和加速度。(d)上手势的实时加速度的细节。实线和虚线分别表示X轴和z轴的加速度。
我们认为确定加速度曲线的精确形状不是关键的,但加速度的在两个轴上的总的符号变化对于唯一区分7种手势中的任何一个是必须的:上,下,左,右,打钩,圆圈,和交叉。这是本文所讨论的识别算法的基础。例如,上手势在Z轴上加速度变化按顺序分是:负-正-负(正Z方向朝下),并在x轴上几乎没有加速度;对于圆圈的手势,在X轴上的加速度:正 - 负 - 正,在z轴上的加速度:负 - 正 - 负 - 正。
实验表明这七种手势中的每种手势都有一个特殊的符号变化顺序,运动学的分析也证明了这一点。
一只手在执行一个手势经历的运动在时间上是非直观的。例如,一个简单的手势可以被分解成几个加速和减速阶段。如图1(b)所示,向上的手势是实际由运从点1至点2的运动组成,然后回到点1。在起点1,中点2与终点1的速度全是零。为了分析方便,第3点是点1和点2之间加速度符号改变的点,并且点4点2和点1之间加速度符号改变的点。然后加速度变化可以描述为:
1 3:在z轴的初始加速度为负(因为z轴正方向向下);速度值在点3从零变化到最大值;加速度值在点3的值为零。
3 4:在z轴的初始加速度为正;速度值在点4从负变化到正向最大,加速度值在点4变为零。
4 1:在z轴的初始加速度为负;速度值从正变为零,并且加速度值和速度值在点1变为零。
上述分析结果如图1(c)所示。 图 1(d)是实际的上手势加速度点组成的曲线,其中虚线是Z轴上的加速度值,实线是X轴上的加速度值。从图1(d),我们注意到,传感器测得的数据存在噪声。然而,噪声不影响加速度曲线的趋势,因此,根据上述方法的手势分析在不使用噪声滤波算法的情况下仍然有效,这样就不会给CPU增加计算负担,因为没有了噪声滤波算法。图1(c)中预测的加速模式与图1(d)的实际加速度曲线图比较,可以得出结论,实际加速度的趋势与预测相同。
在分析了其他手势之后,发现他们都有唯一的加速度特征作为区分的根据。下手势与上手势相似但是在方向上有变化,左右手势与上手势也相似,但是在运动轴上有变化。对勾,圆圈和交叉更复杂,因为它们同时具有x轴和z轴两个方向的加速度,但两个轴上的加速度可以分开和分解,分解后运动趋势变得与上述的例子类似。所述的每个手势趋势的唯一性使识别算法成为可能,在本文所提出的算法是基于七个手势的基本运动特征。
3 传感系统概述
A.传感器概述
在我们的手势运动数据收集实验中使用的传感器系统如图2所示,它基本上是MEMS 3轴加速度传感芯片与数据管理模块和蓝牙无线数据芯片集成在一起。基于传感器系统,本文中所描述的算法得到执行,并能在PC上运行。这种传感器检测系统的硬件架构细节是由我们的组中的人进行设计的。传感系统最近已经在以一个更紧凑的形式商品化 [21]。
图2 用于手势识别的传感模块外形图 (设备的尺寸是长6cm,宽4.5cm,高2.5厘米 ).
B.系统的工作流程
当传感检测系统打开时,MEMS传感器检测三个相互垂直方向上的加速度并经由蓝牙协议传输到PC。手势动作数据接下来会经过一个分割程序,这个程序会自动识别每一个手势的开始和结束,以便只有这些端点之间的数据被处理并提取特征。随后,处理后的数据会被比较程序分类,来确定所做的手势识别。该系统的工作流程如图 3所示。
图3 基于MEMS传感器的手势识别流程
4 手势分割
A.数据采集
用传感检测系统收集可靠的手势数据,实验项目在数据采集阶段应遵循以下指导方针:
bull;传感装置应在整个数据采集过程中水平地放置(即,图2中的传感器芯片的x-y平面朝向地面)。
bull;两个手势之间的时间间隔应不小于0.2秒,这样分割程序就可以按一定的顺序将手势一个一个分开。
bull;执行的手势应该和图4指示的手势一样。
图4 七种手势运动
B.手势分割
1)数据预处理:从传感器接收的原始数据经过两个过程进行预处理:a)时间序列数据中的垂直轴线偏移的消除,可以通过减去数据集平均值的每个数据点来实现;因此,数据集表明了当没有加速度时垂直轴的数据为零; b)一种过滤器被应用到数据集来消除高频噪声的数据。
2)分割:该分割算法的目的是在手势序列的数据集中找到每个手势的识别端点。该算法检查的所有数据点的各种条件,并挑选出最可能的数据点作为手势识别端点。在我们的算法中确定所述手势端点的条件是:a)点的幅度(数据点的纵坐标值);b)点距离(两点的x坐标之间的差);c)平均值(选定点的左侧和右侧的y坐标的平均值); d)与最近的交叉点的距离(一个选定点与“交叉点”之间的距离多远,交叉点即加速度曲线上从负变到正或者从正变到负的点);e)连续两个点之间标志的变化。利用这5个不同的条件检查所有点,各轴运动数据的端点就能确定。因为,所有x轴和z轴加速度数据可以通过这五个条件区分开来,每个手势序列数据都能化为两个矩阵。
Fig. 5. Segmentation of a seven-gesture sequence in the order up-down-leftright-tick-circle-cross.
矩阵第一行上的数据是手势的开始点数据,第二行中与第一行同列的元素是相同的手势的结束点数据。比较这两个矩阵的相同的列数据,如果在某个轴上的一对端点,靠近另一轴的一对端点,则有一对端点将被淘汰。端点的最终确定是通过被给予的一对一对的数据点集最大加速度值与所有点加速度最大值的平均值进行比较得来的。如果前者太小,那么该点对将被淘汰。举个例子,x轴和z轴的最终端点在图5中用圆圈标记了出来。
获得每个手势的端点之后,由于每一个手势具有一个起点和一个终点,手势的数量变得明显,即最后的端点矩阵的列的数量就是手势的数量。
5 模式一:基于符号序列和霍普菲尔德神经网络的手势识别
1)特征提取:通过比较同一手势在x轴和y轴上加速度的最大值和平均值并且设置相应的标志,为了缓解运算需求,将只在一个方向上有加速度的手势(上、下、左、右)与两个轴上有加速度的手势(圆圈、打钩、交叉)区分开来。
为了减少手作出手势不稳定的影响,该算法使用了一定数量的加速度点的平均值来确定符号序列,这些加速度点是根据所述手势的持续时间动态设置的。
特征提取过程如下:检查一个手势第一平均点的符号,存储在手势码,接下来检测的符号改变的次数并按顺序把所有符号存储在手势码里。因此,对于图6所示手势。我们得到的代码:1,1,1,1,特征提取过程大大减少了数据量,图6是符号序列生成的一个例子。整个特征提取过程的变换如图7所示。
图6 手势符号序列
图7 特征提取转换
2)手势编码:在识别之前,所获得的手势码应第一个编码,以便它可以通过Hopfield网络恢复。从我们的实验中,我们发现一个手势在一个轴上符号的最大数量是四,因此,如果x和z轴符号序列组合起来,一个手势代码的符号数量为八。但是,由于Hopfield网络的输入只能是“1”或“-1”,我们对正号,负号和零的编码规则如下:
“1,1”代表正号;
“-1,-1”代表负号;
“1,-1”代表0。
因此,每个手势有唯一的16数字码。例如,图6中手势的第一个符号是正,所以“1,1”被存储在手势码里。手势数据有三个后续符号的变化:从正到负,再由负到正,并最终从正到负;所以“一1,一1”,“1,1”和“一1,一1”被存储到所述手势的手势码里,在手势码里的其它符号都应该设置为零,可以通过“1,一1”来表示。
3)Hopfield网络的联想记忆:Hopfield网络作为一种恢复机制使得识别算法具有更高的容错性。当输入的部分数据丢失或错误时,网络仍然可以在已经预先存储的数据库里检索到最可能的模式。因此,如果有一个不严重偏差,则神经网络将有助于该手势码正确地恢复。要使用Hopfield网络作联想记忆,权重矩阵应首先被构建;权重矩阵的构建也是信息在存储的过程。权重矩阵是[18]
其中,sp被存储的模式,P是被存储模式的数量,I是确认矩阵。7个手势的标准模式在表I中被列了出来。
以这种方式构建的权重矩阵保证了权重矩阵是对称的零对角元素,并根据Hopfield神经网络的属性,网络将是稳定的,并在经过一定次数的迭代之后可以检索到最接近的标准模式。如果输入到该网络的是sq,则检索到的v(n)就是输出。
4)手势比较:手势代码恢复后,将各手势码与标准手势码相比较。该比较是通过计算两个码之间的差,即,最小的差表示是最可能的手势并输出识别结果。
6 模式二:基于速度增量的手势识别
这种方法的本质是利用速度增量或由加速度曲线和x轴包围的面积等不同的特征来实现分类。一个手势在一个轴上的加速度首先根据符号分配。如图8所示,加速度图案可以通过标记区域来表示。这些区域的物理意义是速度的增加或减少。由于标志序列的信息可能在减少,然而速度增量或区域序列包含更多分辨信息,所以这种方法是一个处理复杂手势的更好方法。
图8 生成的面积序列 (a)加速度部分和(b)由
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[153795],资料为PDF文档或Word文档,PDF文档可免费转换为Word
您可能感兴趣的文章
- 2.3港口吞吐量预测外文翻译资料
- 使用多标准移动通信分层遗传算法的阻抗 匹配网络的宽带优化外文翻译资料
- 移动RFID标签阅读与非重叠串联阅读器在输送带的应用外文翻译资料
- 利用数字图像进行的全场应变测量方法外文翻译资料
- 自然灾害中并发事件的多种应急资源的分配外文翻译资料
- 基于主机的卡仿真:开发,安全和生态系统影响分析外文翻译资料
- 实现基于Android智能手机的主机卡仿真模式作为替代ISO 14443A标准的Arduino NFC模块外文翻译资料
- 探索出行方式选择和出行链模式复杂性之间的关系外文翻译资料
- 信息系统研究、教育和实践的基本立场及其影响外文翻译资料
- 仓储和MH系统决策模型的设计优化与管理外文翻译资料

